
The Winners from DeepSeek, Nvidia, and The Outlook in AI
A tour of the space & AI-exposed stocks

A brief tour of DeepSeek’s key innovations
So it looks like the Chinese AI startup DeepSeek has made two major breakthroughs. The first is really a series of better algorithms that dramatically lower the cost of training. Reading through the paper, the most important of these look to be DeepSeek’s Multi-Head Latent Attention (MLA), a finer-grained mixture-of-experts (MoE) architecture, Multi-Token Prediction (MTP) and running many operations in training in 8-bit floating points as opposed to everything in 32-bit.
The results are huge gains in efficiency and according to DeepSeek, one could train their model in less than 2.8 million H800 hours. The H800 is the Nvidia Hopper GPU which China used to be allowed to import. Assuming a cost to rent one of these GPUs at $2 per hour, this leads to estimated overall training cost of around $5.6 million:

We will only be able to tell whether these assertions are fully true once these algorithms have been replicated in training. There’s no doubt that US-based AI labs will try these out so we should know fairly soon. But having read the papers, at this stage we don’t see any reason to doubt the above table.
While the first innovation should lower AI compute costs, the second innovation should actually increase compute costs as it will boost the demand for inference-time, more on this in a bit. So this second innovation is in DeepSeek’s DeepThink Model, also called R1, which was trained with reinforcement learning on the base model above. The goal of this to provide DeepThink with chain-of-thought capabilities, similar to OpenAI’s o1 model. Basically the way this process worked was that DeepThink was given rewards during training, so that if it gave a correct answer or it made a correct step in its thinking process, the model could update its parameters based on the size of the reward. The goal of this process is to learn by trial-and-error and large amounts of iteration so that the model can become really good at its tasks.
Reinforcement learning is nothing new and was actually the hottest area in AI just a few years ago until LLMs came along. It’s actually the way how both AlphaGo and AlphaFold were trained. The innovation here is that this is the first time that this type of unsupervised reinforcement learning was applied to an LLM. Obviously this type of training works very well for exact sciences types of problems, and this is also the reason why DeepThink is so good in coding and math.
The impact for AI datacenter stocks & Nvidia
So we discussed two sets of innovations above. The first one with the algorithmic improvements for AI workloads is what really caused the sell off in AI stocks. The basic theory is that given these huge efficiency improvements combined with the currently massive buildout in AI data centers, once these improvements have been introduced in the models of OpenAI, Google and Meta; six or twelve months from now we’ll have a large amount of excess AI capacity. Causing orders for Nvidia GPUs and other components in the AI data center supply chain to be halted. Obviously the main stocks at risk from DeepSeek’s breakthroughs are those exposed to the buildout of AI data center capacity.
The counter argument of the bulls is that due to these cost improvements, AI demand increases disproportionately resulting in a higher need for AI compute. While in the long term we think that this argument is valid, in the near term i.e. the coming one or two years or so, this will depend on the price elasticity of demand. The way to think about this is if DeepSeek’s improvements reduce the need for compute by 8x in the coming year, but demand only increases 2x, we’re still down 4x in terms of AI capacity which we thought we would need.
So there are two key questions. The first is, assuming all of DeepSeek’s claims are indeed valid, how much of an efficiency improvement these innovations give? And the second is, given these cost improvements, how elastic is AI demand?
On the first question, Dario Amodei — the CEO of Anthropic — thinks that the cost improvement in training is about 4x:
“I think a fair statement is ‘DeepSeek produced a model close to the performance of US models 7-10 months older, for a good deal less cost (but not anywhere near the ratios people have suggested)’. If the historical trend of the cost curve decrease is ~4x per year, that means that in the ordinary course of business — in the normal trends of historical cost decreases like those that happened in 2023 and 2024 — we’d expect a model 3-4x cheaper than 3.5 Sonnet/GPT-4o around now.
Since DeepSeek-V3 is worse than those US frontier models — let’s say by ~2x on the scaling curve, which I think is quite generous to DeepSeek-V3 — that means it would be totally normal, totally ‘on trend’, if DeepSeek-V3 training cost ~8x less than the current US models developed a year ago. I’m not going to give a number but it’s clear from the previous bullet point that even if you take DeepSeek’s training cost at face value, they are on-trend at best and probably not even that. For example this is less steep than the original GPT-4 to Claude 3.5 Sonnet inference price differential (10x), and 3.5 Sonnet is a better model than GPT-4.”
We disagree that DeepSeek V3 is 2x worse than GPT-4 or Sonnet. Having tested the model over the last ten days, the answers are impressive. So it’s probably a good assumption that DeepSeek’s innovations reduce the need for AI compute with 4 to 8x, with the latter being more likely.
On the second question of how elastic the demand for AI compute will be, we can look at history. Efficiency improvements have been a constant in AI research and Amodei estimates they are about 2 to 4x per year, with the rate increasing towards 4x more recently. At the same time we can see that despite these algorithmic improvements, compute requirements of AI models have continued to increase:
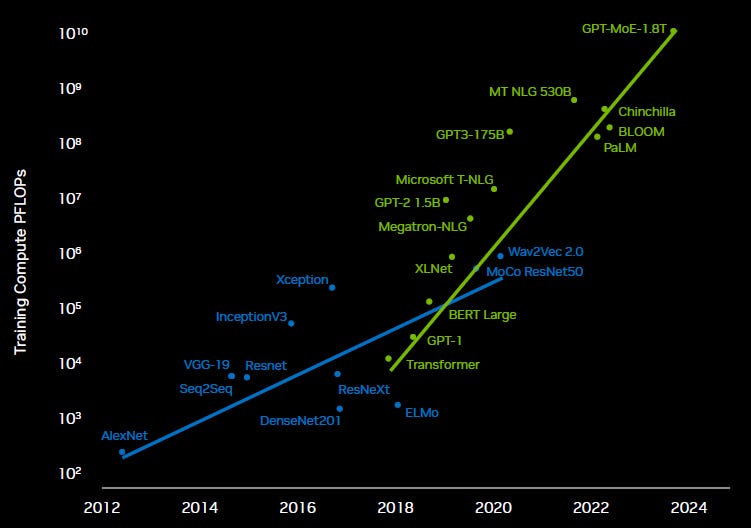
Most of these increases in compute demand have been driven by scaling laws, i.e. the observation that larger AI models trained on larger amounts of data and for larger amounts of time tend to perform better. Scaling laws are still alive and well as several of the leading players in LLMs are talking about 1 and 2 million GPU training clusters. And these will be Blackwell clusters. For comparison, OpenAI’s ChatGPT 4 was trained as 25,000 A100s.
And even more encouraging is that a second scaling law has emerged, this time in inference. The scaling law here is that a larger model that reasons for larger amounts of time tends to comes up with better solutions. And actually, DeepSeek’s breakthroughs with its R1 DeepThink model will benefit the second scaling law. Now that LLMs can develop chain-of-thought reasoning capabilities with unsupervised reinforcement learning, this will result in both more models and much more impressive models with inference-time capabilities. Anecdotally, we never used OpenAI’s o1 as it felt slow and boring, while DeepSeek’s R1 felt much faster and interesting as it displayed how the model was reasoning. So when it comes to the second scaling law, DeepSeek should strongly drive compute demand here.
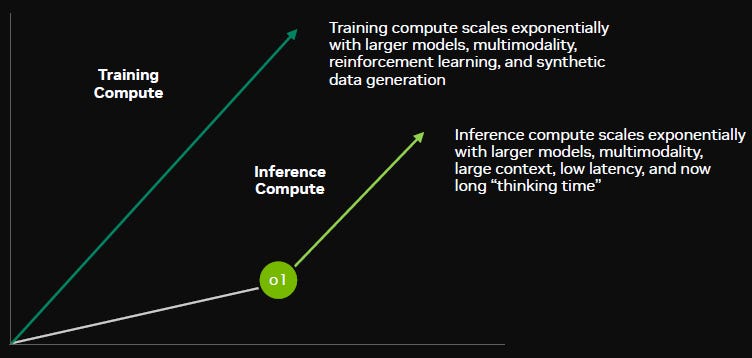
And demand for inference-time will see a further boost once we head into the world of AI agents. The basic idea here is that you allocate a certain task to an AI assistant, who subsequently organizes and delegates all the work to be carried out to various AI agents with their own expertise. An example here could be writing a software program — one agent defines the overall software architecture, another agent writes the functions, the database-expert agent defines the database scheme and the API expert writes the API.
Zuckerberg on Meta’s call had a similar line of reasoning. While DeepSeek’s innovations can drive down the cost of training, more compute will be needed for inference:
“We expect to bring online almost a gigawatt of capacity this year and we're currently building a 2-gigawatt and potentially bigger AI data center. We're planning to fund all of this by AI advances that increase revenue growth.
On DeepSeek, there's a number of novel things that we're still digesting and that we hope to implement in our systems. It's too early to really have a strong opinion on what this means for the trajectory around infrastructure and CapEx. There's already a debate around how much of the compute infrastructure is going towards pre-training versus inference as you get more of these reasoning models. It already seemed pretty likely that the largest pieces aren't necessarily going towards pre-training. But that doesn't mean that you need less compute because one of the new properties that's emerged is the ability to apply more compute at inference-time in order to generate a higher level of intelligence and a higher quality of service.
The field continues to move quickly and I continue to think that investing very heavily in CapEx and infrastructure is going to be a strategic advantage over time. At this point, I would bet that the ability to build out that kind of infrastructure is going to be a major advantage for both the quality of the service and being able to serve the scale that we want to.”
And also Microsoft’s Satya Nadella continues to see AI scaling laws in both training and inference:
“AI scaling laws continue to compound across both pre-training and inference-time compute. We ourselves have been seeing significant efficiency gains in both training and inference for years now. On inference, we have typically seen more than 2x price performance gain for every hardware generation and more than 10x for every model generation due to software optimizations. And as AI becomes more efficient and accessible, we will see exponentially more demand. Therefore, much as we have done with the commercial cloud, we are focused on continuously scaling our fleet globally and maintaining the right balance across training and inference as well as geo distribution.
Azure is the infrastructure layer for AI. We continue to expand our data center capacity in line with both near-term and long-term demand signals. We have more than doubled our overall data center capacity in the last 3 years, and we have added more capacity last year than any other year in our history. And with OpenAI's APIs exclusively running on Azure, customers can count on us to get access to the world's leading models. And OpenAI has a lot more coming soon, so stay tuned.”
So while the long term outlook for AI continues to be bullish, especially in scaling inference-time, the risk for investors is that due the magnitude of DeepSeek’s improvements, we could see an excess in AI capacity 6 to 12 months from now. Resulting in a temporary halt in orders for GPUs and other AI data center components. There’s little doubt that Nvidia and other names in the AI data center supply chain will underperform in that scenario.
However, looking at Nvidia’s valuation, the current forward PE of 30x is already pricing in an earnings correction. The way this works is that cyclical names tend to trade on bottom multiples when the market reckons that earnings are on a cyclical high. So when earnings subsequently go through a cyclical correction, you start to see multiple expansion as the market starts factoring in the next upcycle.
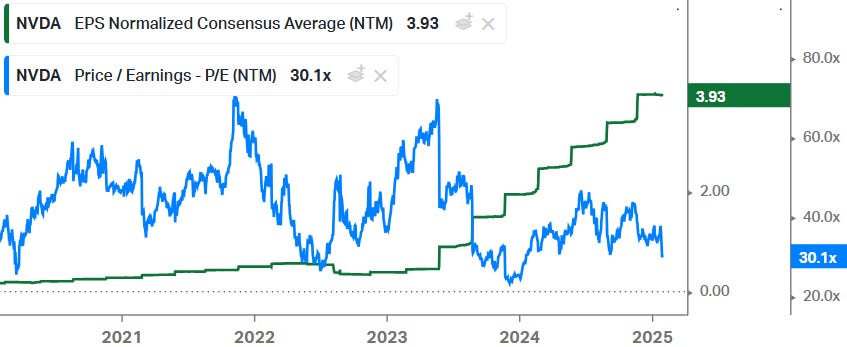
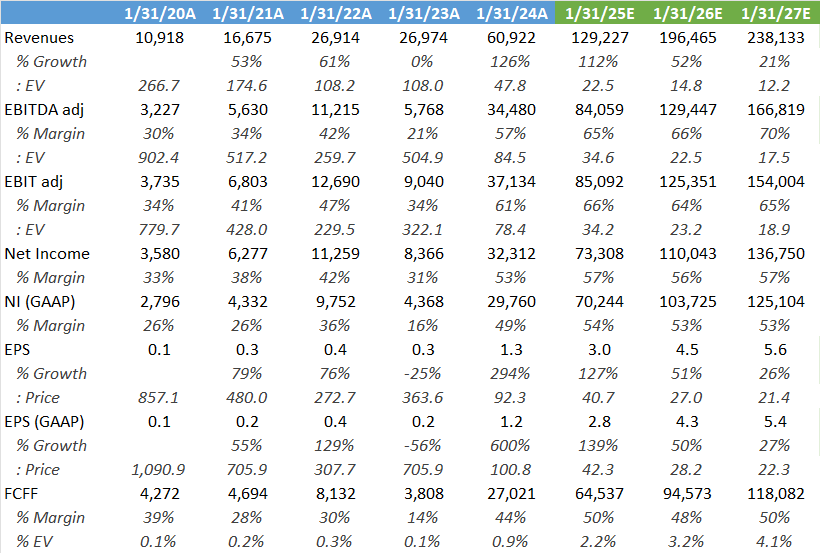
A recent example of that typical scenario is Texas Instruments. As the company’s earnings went into a downturn, the stock’s PE multiple expanded:
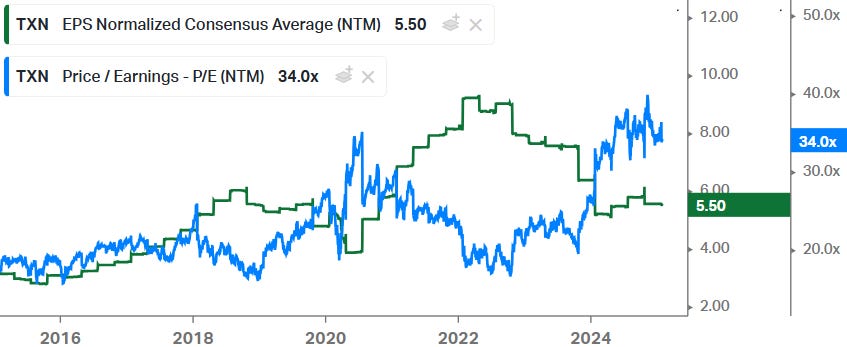
And this limited downside in the share price over the 2023 - 2024 semi contraction. So despite the cyclical nature of TI’s business, the shares held up much better.
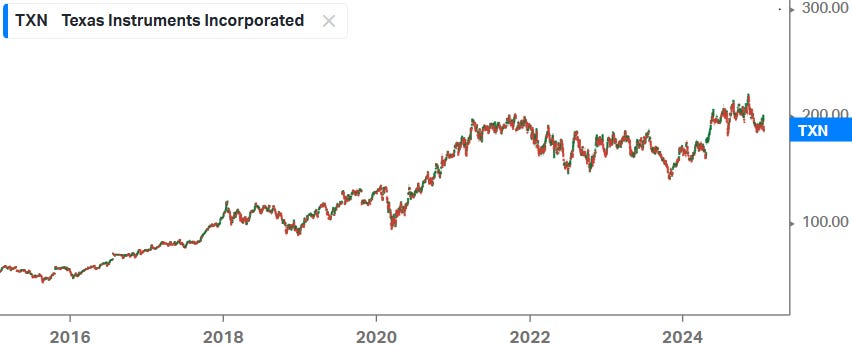
So basically what we’re seeing here is that for quality companies with an attractive long-term growth outlook, investors are willing to hold the shares through the cycle, which reduces share price volatility. That being said, the downside for Nvidia would be if the anticipated earnings correction turns out to be uglier than expected, i.e. a dramatic decline in orders for a substantial period. However, due to the strong scaling laws we’re currently seeing, where especially those in inference-time have a very promising outlook, this risk should be limited.
Nvidia continues to have a long term attractive outlook. The long term CAGR in AI demand should be steep due to the breadth of applications where AI can be applied, the huge sizes of some of these markets, and scaling laws. Nvidia is a stock which has really been climbing a wall of worries over the last few years. Ever since the AI boom started and Nvidia gave its first huge growth outlook in May of ‘23, many were already screaming bubble. Since this share price pop, the shares have tripled again even taking into account the sell off of last week.
Investors can still make an attractive IRR in Nvidia. Putting fiscal year ‘27 consensus numbers from Wall Street on a 30x forward PE results in an IRR of 45%. And we know from a channel check with Amazon that indeed a large increase in orders is coming again this year, although the largest increase in orders will be for their own internally developed accelerators. Cloud customers tend to use Nvidia whereas the hyperscalers themselves are trying to move AI workloads to their own silicon.
We delved deeper into the market share battle between Nvidia and ASIC accelerators below. The hyperscalers are obviously huge clients, and who are extremely good at writing software stacks to abstract away the hardware layers underneath. These software stacks are becoming ever more advanced and with programming languages that resemble Nvidia’s CUDA, making it easier for AI engineers to get up to speed with them.

So Nvidia continues to have attractions here. It has basically locked in the enterprise AI market which should see a high CAGR for the foreseeable future. That being said, a lot of investors will have made substantial money in this name already, so it’s not unwise to lock in some profits and allocate these to other names with perhaps a better risk-reward.
In this article, we will tour a large variety of AI-exposed names which should get a boost from DeepSeek. Two obvious areas are companies developing AI apps and then the semis deployed at the edge to run those AI apps. Both of these should benefit due to the increases in AI demand coming from DeepSeek lowering the cost curve, as well as from the rise of chain-of-thought reasoning.
In the following chapters of this article, we’ll flag our favorite stock picks as well as well-known names which we would avoid at this stage. Finally, we’ll create an AI basket from our buy ideas. Whereas most analysts have been purely focused on AI-datacenter-capex related stocks, we’re taking a much broader approach by also investing in AI software, robotic applications and edge semis. Long term, the first two should turn out to be the largest investment opportunities given the huge sizes of these markets.