

One of the biggest surprises this week was Nvidia’s $2 billion equity investment into Synopsys. Synopsys is one of the two dominant EDA players, together with Cadence, i.e. software solutions which take care of chip design and verification. The latter is extremely compute heavy and is still running on CPUs, a process taking up weeks and months. With this partnership, Nvidia and Synopsys will work on moving these physics-based simulations onto CUDA, Nvidia’s GPU computing platform. This is not an easy feat as to leverage Nvidia’s GPUs, code has to be parallelized.
The beauty of coding for CPUs is that it is extremely simple, you can leverage languages such as C, Fortran, Rust, etc., and even make use of multi-threading to parallelize tasks over multiple CPU cores where possible. However, to move these workloads onto GPUs, this requires a complete algorithmic and codebase overhaul. GPUs demand massive thread-level parallelism with tens of thousands of threads, and a codebase that has to be rewritten for CUDA. This code has been built up over decades, and so rewriting it is an enormous task. This is precisely the reason why it has not been done before despite GPUs being much faster.
What will no doubt help here is that LLMs have gotten extremely good at coding, and so they can now take over large parts of this workload. Basically, we will have GPUs creating code to run on GPUs, creating a virtuous circle of GPU demand.
This is Synopsys’ CEO on how verification is currently a major compute bottleneck in chip design:
“We started redesigning some of our products about 7 years ago on NVIDIA GPU using the CUDA layer and in a number of cases, we’ve seen a significant speed up. When you talk about 10x, 15x, 20x speed up on a work that may take 2, 3 weeks and bring it down to hours; customers will adopt it. The bottleneck of designing these complex chips or complex systems is limited by the computation requirement to verify these systems. The worst thing you can do is assume that you’re ready to go, launch a chip and it doesn’t work as intended. That costs hundreds of millions of dollars. So, you spend a lot of energy in the design and simulation phase. We have a number of products already in use at customers, still very early stages in terms of a broad adoption, but that’s why we refer to an expanded opportunity for both companies.”
Jensen highlighted how EDA and CAD software will play a major role in digital copies of the physical world, i.e. digital twins:
“The expansion of the market opportunity for Synopsys goes from the EDA industry – addressing a several hundred billion dollar chip industry – to now addressing a multitrillion dollar, every product industry. In the future, every product will be designed in digital twins. This partnership essentially enables this industry to address the entire R&D budget of the whole world’s GDP. Everything that’s going to get designed and built will be done first in a digital twin.
In 2016, 90% of the world’s scientific supercomputers running physical and biological simulations were general purpose CPUs. Today, it has flipped completely, CPU-only supercomputers are 10%. NVIDIA-accelerated computing is now 90% of the world’s physical science simulation computers. This is going to happen also in the EDA industry. For industries that are fundamentally based on physics, this capability is really important.
The challenge, of course, is to reformulate the algorithms so that it could be accelerated on CUDA. And that is a multiyear journey. It took some 7 years probably to do cuLitho. Reformulating Synopsys’ applications to take advantage of this acceleration is what this is all about. All of it will be CUDA accelerated over time. And so we’ve got a lot of work to do, but that’s what this partnership is really about, focusing the two engineering teams across the entire companies so that we could take this capability to market as soon as possible.
The partnership is nonexclusive. There’s no obligations whatsoever for Synopsys to only buy NVIDIA. And they’re welcome to continue to work with their rich ecosystem of chip partners, and we’re going to continue to work with our ecosystem of really important EDA and CAD partners like Cadence, Siemens and Dassault. We also partner with Intel, all of NVIDIA’s EDA – the way we do chip design and system engineering today – is still largely based on x86 CPUs. This is really the beginning of that platform shift so that in the future, that’s going to be accelerated by NVIDIA GPUs. And I’d be delighted for all of the chip industry to buy NVIDIA GPUs for designing their chips.”
This is obviously a bit of a sideshow for Nvidia as GPU-based chip design will be a small end-market compared to AI. However, it is of key strategic importance to accelerate their own chip design cycle. Nvidia has recently moved to a one year cadence in releasing a new major chip, and no doubt removing the verification bottleneck will have a major positive impact once this work is complete.
Clearly this is an evolution that can have major impacts on the chip design industry overall. Most notably, it will bring down costs as weeks of chip simulation can be reduced to a single day or less. This opens the door for more chip experimentation and also more custom designs to be done, even by less experienced players who have the capital (e.g. large enterprises), as you can iterate on your chip designs quickly and remove bugs via verification.
The winners from this should be the EDA companies, Synopsys and Cadence, as lower chip design costs should boost demand for chip design software from more enterprises. Additionally, Synopsys and Cadence have solid pricing power. When they can provide a tool that speeds up work by 20x, they will have the ability to raise prices for GPU-accelerated modules. While Nvidia’s investment could give Synopsys an edge here, also Cadence is pursuing GPU accelerated workloads and has historically been able to build out a solid simulation portfolio.
Marvell’s New Data Center Tech
Marvell made a new acquisition to increase the company’s focus towards the data center and AI in particular. This is a strategy that has been working well, with the company’s revenues growing 41% year-over-year this quarter (excluding the recently divested automotive ethernet business to Infineon), and the data center end-market now comprising 74% of revenues. This is Marvell’s CEO on the tech and team they’ll be acquiring, which sounds pretty interesting:
“I’m excited to share details on the strategic acquisition we announced today of Celestial AI, which brings an entirely new disruptive technology, a photonic fabric platform purpose-built for next-generation scale-up interconnect. This acquisition is the latest in a series of decisive moves to further strengthen our data center portfolio. Since 2019, we have continued to increase our focus on the data center, divesting our WiFi business and acquiring Avera, Aquantia, Inphi and Innovium. These transactions have driven significant revenue growth and scale, and have each proven to be an absolute home run. The acquisition is expected to close in the first quarter of next year, subject to regulatory reviews in the United States.
AI is reshaping data center architecture at an unprecedented speed. Next-generation accelerated systems are no longer confined to a single rack, they are evolving into multi-rack scale-up fabrics that connect hundreds of XPUs in a high-bandwidth and ultra-low latency any-to-any fashion. These advanced fabrics demand purpose-built switches and interconnects, creating a new TAM for companies like Marvell. Industry analysts are forecasting the merchant portion of the scale-up switch market to approach $6 billion in revenue in 2030. On the interconnect side, as it attaches to both the XPU and the switch, the opportunity actually doubles to over $10 billion. These are both very large and incremental opportunities for Marvell.
As we first evaluated Celestial AI, it reminded us of our early look at Inphi and the products we saw in their PAM technology to transform the scale-out interconnect market. We see even greater potential for Celestial AI’s photonic fabric to transform scale up interconnect. Interconnect technology is critical to couple hundreds of XPUs together. Copper-based interconnects used in today’s scale-up systems are approaching their fundamental limits in reach and bandwidth, creating a compelling need for optical solutions. Celestial AI’s photonic fabric technology was purpose-built for this inflection. It enables large AI clusters that scale both within and across racks using a high bandwidth, low latency, low power and cost-effective optical fabric. This breakthrough enables a true optical solution with greater than 2x the power efficiency of copper interconnects, but with far longer reach and significantly higher bandwidth.
Celestial AI’s solution provides nanosecond class latency and the thermal stability is a significant competitive differentiator. It enables reliable operation in the extreme thermal environments created by large multi-kilowatt XPUs. This allows the photonics technology to be co-packaged vertically with high-power XPUs and switches in a 3D package, enabling the photonic connection to be made directly into the XPU rather than from the edge of the die. This stands in sharp contrast to many other CPO implementations where the photonics engine must connect at the die edge. Celestial AI’s approach results in a more compact and integrated solution, freeing up highly valuable die edge beachfront that can be repurposed to significantly increase the amount of HBM within the XPU package.
Celestial AI’s first-generation product is a photonic fabric chiplet (PF chiplet), which integrates all the required electrical and optical components. This delivers an unprecedented 16 terabits per second of bandwidth in a single chiplet, 10x the capacity of today’s state-of-the-art 1.6T ports used in scale-out applications. Celestial AI is deeply engaged with multiple hyperscalers and ecosystem partners and has already secured a major design win with one of the world’s largest hyperscalers who plans to use PF chiplets in its next-generation scale-up architecture. These PF chiplets will be co-packaged into both the hyperscaler’s custom XPUs and scale-up switches to provide connectivity.
This is just the beginning of a broad set of new applications which can be enabled from this technology. Our base case forecast shows Celestial AI’s revenue reaching a $500 million annualized run rate in the fourth quarter of fiscal 2028, doubling to a $1 billion run rate by the fourth quarter of fiscal 2029.”
Marvell’s fiscal ‘28 ends in January of ‘28, so significant revenues will start coming in two years from now (Q4 of calendar ‘27). The main goal of this new tech is to scale up (providing low latencies) across multiple racks. Traditionally, when you add racks to your compute, this is called scaling out (or horizontal scaling). However, Marvell-Celestial AI are calling this scale up here – a term traditionally used to refer to adding more compute into a single server or rack – as due to low latencies, they could make a cluster of 5-10 racks behave like one rack.
Current scale-up fabrics (like NVIDIA’s NVLink or Credo’s AECs) rely on copper, which confines a computing node to a single rack (e.g. 72 GPUs). To grow larger, you currently have to step down to slower scale-out networks such as Ethernet or InfiniBand, which forms a bottleneck especially in AI training today. During the Q&A, it became clear that Amazon AWS will be the first customer, and so this tech will first be implemented for Trainium-based AI training clusters. As shipments start in Q4 2027, this will be either for Trainium v3 or v4 based training clusters.

With this acquisition, Marvell is building out their data center connectivity portfolio with what looks like a very promising next-gen technology – high bandwidth, low latency, long reach, and thermal stability. Marvell has a current stronghold in DSP-based connectivity (800G and 1.6T pluggables), which are the go-to for hyperscalers to wire up AI clusters. The company acquired this expertise with the Inphi deal in ‘21, which was obviously a great investment and it is currently the key driver of growth.
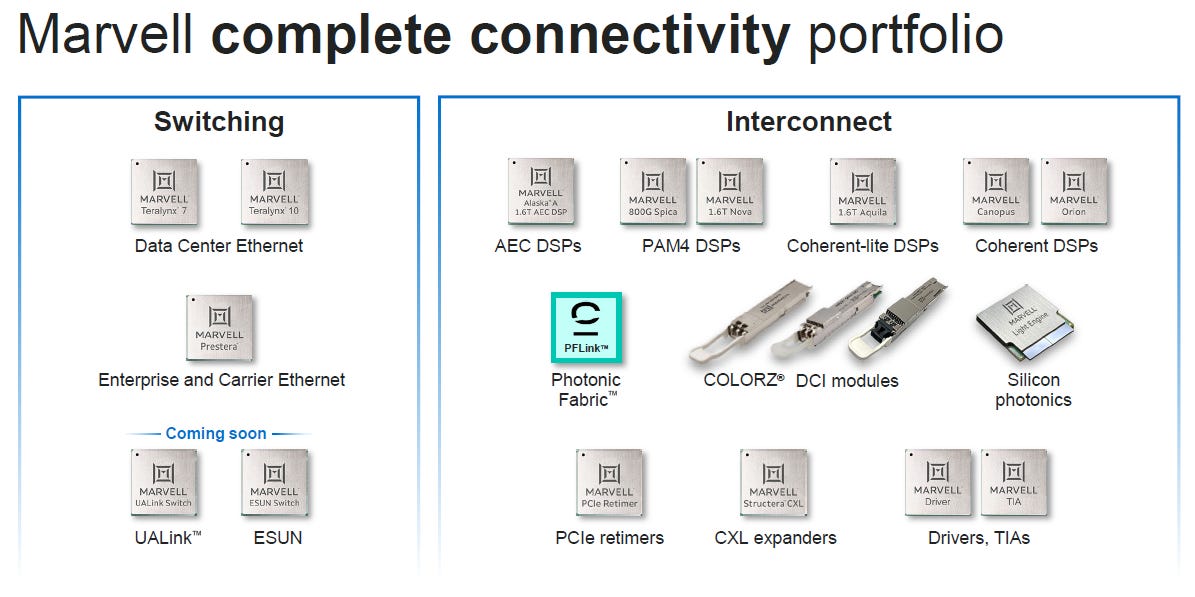
So, the company has a fairly dominant market share in DSPs, but the main concern would be increasing competition from Broadcom which is launching competitive products. However, end-market strength is expected to offset headwinds from competitive pressures. This is HSBC on these dynamics:
“We believe Marvell is maintaining its market leadership in this segment through its 800G PAM4 DSP, which is seeing strong demand, and the launch of the subsequent 200 gig per lane 1.6T PAM4 solution, for which the company anticipates accelerating adoption over the next few quarters. However, we believe its market leadership may be threatened by Broadcom, which has caught up with the launch of its own 800G and 1.6T DSP solutions. As a result, while we do believe that the growth of its AI optical business, which is primarily driven by PAM4 DSP solutions, will decelerate — we believe the growth would still be higher than Street estimates due to the overall TAM expansion.
Amidst the massive AI infra demand expanding beyond traditional hyperscalers and into enterprise, sovereign AI, etc., the demand for DSP solutions continues to rise. Hence, while we expect AI optical business y-o-y growth to decelerate from 54% in FY26e to 38% in FY27e and 20% in FY28e, our FY27e and FY28e estimates remain above consensus estimates of 20% y-o-y growth in FY27e and 3% y-o-y contraction in FY28e. Our bullish estimates are based on our belief that while 800G will continue seeing strong momentum, the 1.6T solution will also see faster adoption driven by the TAM expansion.”
Next, we’ll dive further into Marvell. Will Marvell get disrupted? Is it time to take profits after the strong share price rally since September? We’ll provide much more analysis below..