
The battles for the HBM and AI cloud markets, AMD's large opportunity no one is talking about, SK hynix the deep value AI play, and KLA signals a semicap ramp
Outlook in leading edge semiconductors and AI

The battle for the HBM market
High bandwidth memory (HBM) has become a key enabler of the wave of innovation in LLMs by providing GPUs with high speed access to stacks of co-packaged DRAM, speeding up both AI training and inferencing. In HBM, DRAM dies are connected by high-bandwidth through-silicon-vias (TSVs) and microbumps to a logic die at the bottom of the stack. The latter handles the communication with the centrally placed GPU over an interposer:

In the future, instead of microbumps, a transition will be made to hybrid bonding technology, something which Dutch advanced packaging equipment provider BE Semi has been working on. However, SK hynix thinks this transition can be pushed back, given that it is more crucial to first scale up HBM production to meet the vast demand in AI. This is SK hynix’s CFO, who frequently does an excellent solo conference call with analysts:
“If the packaging height configuration for HBM is relaxed, then we do expect the adoption of hybrid bonding technology to be pushed back. Given the complexity of the technology, there may be some productivity and quality issues, especially in the early days of adoption. And for the sake of reliable supply and cost of HBM, it would be better to wait until the technology reaches sufficient maturity.”
Each of the three players in the HBM market gave a strong business outlook on their recent calls, and both SK hynix and Micron mentioned that their capacity is already fully booked for both this year and the next. As DRAM manufacturing capacity shifts to ramp up HBM production, pricing in the DRAM market has been making a strong recovery with prices now up around 80% since the fourth quarter of last year. As such, also Micron has now been seeing a strong recovery in its DRAM revenues, whereas for SK hynix this already started in the second quarter of last year as the company is the key supplier for Nvidia’s H100:
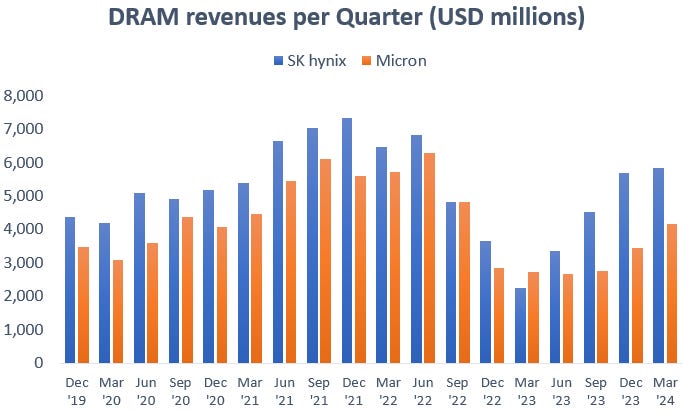
This is SK hynix’s CFO again, this time on the outlook in DRAM and HBM:
“AI servers continued to see strong demand while DRAM and NAND prices rose more than what we expected in the beginning of the quarter, which makes us believe that the memory market is clearly entering into a full recovery phase. DRAM ASP increased by over 20% compared to the previous quarter with prices rising across all product lines for two consecutive quarters. Meanwhile, prioritization of premium products like HBM will lead to a production limitation on general DRAM products, which will eventually accelerate inventory depletion across the industry once the demand for the conventional market improves. HBM requires more wafer capacity than regular DRAM because its die size is roughly double that of regular DRAM. Thus, the wafer capacity for regular DRAM this year is expected to be limited. Favorable pricing environment is expected to continue throughout the year and thus the memory market in 2024 is projected to reach a revenue size comparable to that of past peak cycles.
Demand visibility in HBM is becoming clearer than it was just half a year ago. And regarding concerns that the HBM market may face oversupply as vendors expand their capacity, well, the HBM market is set to keep rapidly growing in 2024 and beyond as data and model sizes grow for reasons such as increasing parameters and also the growing use cases among end users. Based on our product competitiveness and large-scale mass production experience, we are now in discussion about long-term projects through 2025 and beyond with quite a number of existing and potential customers.
About the capacity for 2025, it is currently under discussion with our customers and we will be ready to grow with our customers in line with the AI market growth through timely investment and capacity expansion. Due to the rapidly growing demand for HBM together with the new investment decision for the M15X fab, the company's CapEx this year is expected to be somewhat higher than the amount that was planned initially.”
SK hynix was in the sweet spot last year being the key supplier to Nvidia’s H100 with a share of around 80%. Meanwhile, the two other DRAM makers, Samsung and Micron, are now stepping up R&D with the goal of taking a significant share as well. Both companies have already sent out samples to Nvidia for their new 12-layer HBM3E products, whereas SK hynix still needs to do so later this month.
There have been reports that SK hynix has a superior manufacturing process with its Mass Reflow Molded Underfill (MR-MUF), however, both Samsung and Micron sounded confident on their coming growth in HBM. In addition, Nvidia has already qualified Micron’s 8-layer HBM3E and will use it as well in the recently launched H200, diversifying its HBM supplier base further. This is Samsung’s head of Memory on the latest call:
“We started mass production of HBM3E 8-high this month to address the demand for generative AI and we plan to mass produce 12-high products within the second quarter. We have already shipped samples of our 12-layer HBM3E, which was the first in the industry. We're going to make a quick transition to 3E in our capacity in the second half of the year and focus on capturing the high-capacity HBM demand. In 2024, our HBM bit supply actually has expanded by more than threefold versus last year. And in 2025, we will continue to expand supply by at least 2x or more year-on-year, and we're already in talks with our customers on that supply.”
This is Micron’s CEO on their plans in HBM:
“Earlier this month, we sampled our 12-high HBM3E product, which provides 50% increased capacity of DRAM per cube to 36 gigabytes. This increase in capacity allows our customers to pack more memory per GPU, enabling more powerful AI training and inference solutions. We expect 12-high HBM3E will start ramping in high-volume production and increase in mix throughout 2025. We have a robust road map, and we are confident we will maintain our technology leadership with HBM4, the next generation, which will provide further performance and capacity enhancements.
As discussed previously, the ramp of HBM production will constrain supply growth in non-HBM products. Industry-wide, HBM3E consumes approximately 3x the wafer supply as DDR5 (DRAM) to produce a given number of bits in the same technology node. With increased performance and packaging complexity across the industry, we expect the trade ratio for HBM4 to be even higher than the trade ratio for HBM3E. We anticipate strong HBM demand due to AI, combined with increasing silicon intensity of the HBM roadmap, to contribute to tight supply conditions for DRAM across all end-markets.”
So Samsung is already starting high volume production of 12-layer HBM this quarter with SK hynix now having fallen a quarter behind, starting high volume manufacturing in Q3. At the same time, third competitor Micron will enter the competitive landscape, ramping up high volume manufacturing as well one quarter behind SK hynix. Korean media reported that Samsung has signed a $3 billion agreement with AMD to supply 12-layer HBM3e for the new Instinct GPUs. In return, Samsung apparently agreed to purchase a number of AMD GPUs.
Looking at valuation, whereas we’ll likely be heading into the mother of all memory cycles, valuation for SK hynix isn’t stretched at all at 2x forward Sales combined with a 6x forward PE:
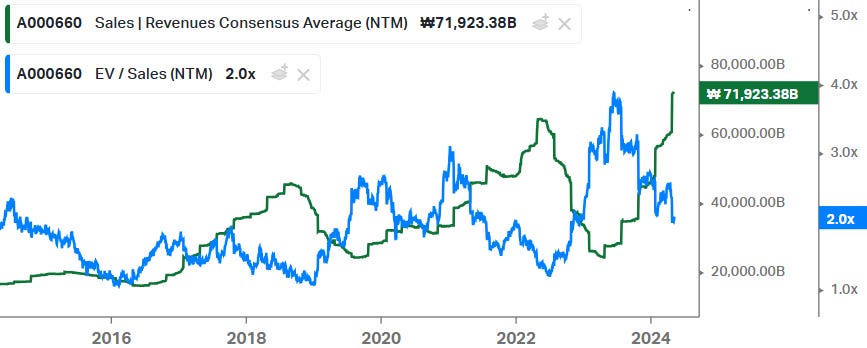
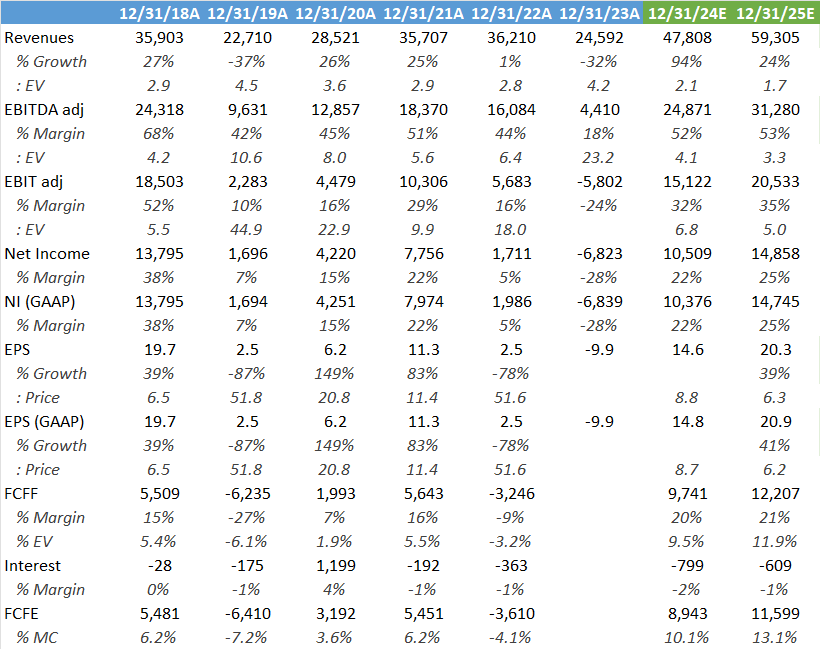
In fact, on consensus numbers, we should be heading to a 10% FCF yield for the company, which looks attractive for one of the most exposed companies in semis to the AI investment cycle:
For comparison, Micron trades already on much higher multiples, 4.5x forward Sales combined with a 15.4x 2025 EPS:
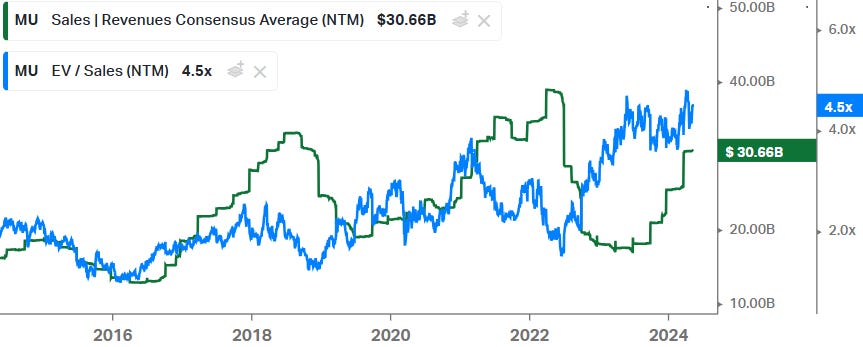
While the FCF yield in ‘25 is only expected to be 4%:
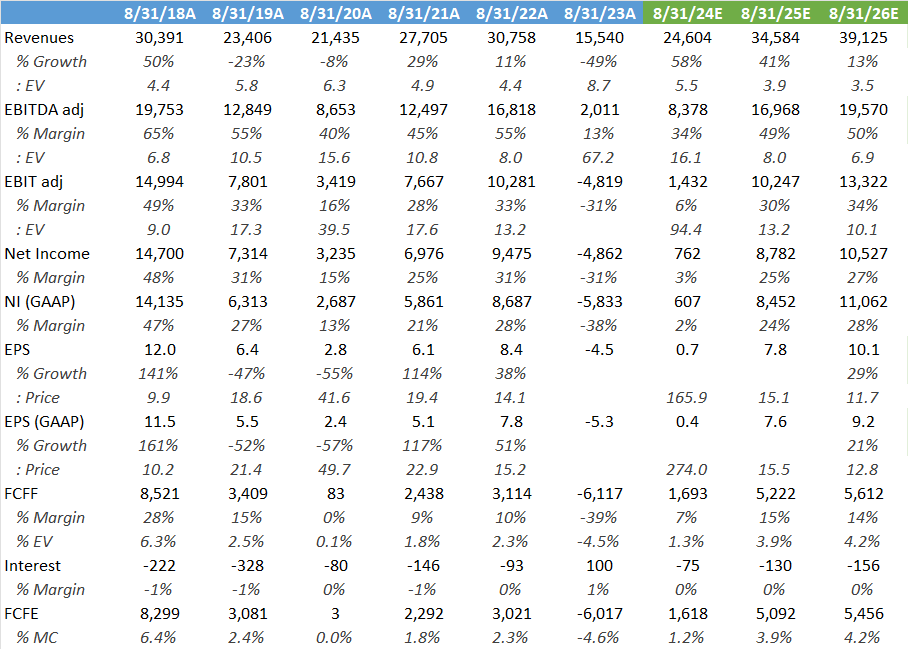
The attraction in DRAM is that we only have three companies competing and the space is enjoying tremendous growth in HBM while we’re only at the start of LLMs really. We’re sort of in a similar stage as we were in 1995 in terms of how the internet was going to change society in the subsequent 25 years. Out of Micron and SK hynix, I would definitely prefer to hold the latter. Not only has the company a far strong position in HBM, but the shares are also showing attractive value in my opinion.
The battle for the AI cloud
Each of the three public clouds — Amazon AWS, Microsoft Azure and Google Cloud Platform — have been keen to highlight their availability of Nvidia GPUs in their datacenters. However, it’s also clear that they’re pricing their custom accelerators at very attractive rates with the aim of moving more AI workloads onto them over time. This is Amazon’s CEO:
“We have the broadest selection of NVIDIA compute instances around, but demand for our custom silicon, Trainium and Inferentia, is quite high given its favorable price performance benefits relative to available alternatives. Larger quantities of our latest generation Trainium 2 are coming in the second half of 2024 and early 2025.”
Google made similar comments with respect to their TPUs and naturally a big focus for them has been to reduce costs to run these algorithms. Currently Google Search is their main profit contributor, and the margins on this business are sky high as each search query involves a basic database lookup, which is extremely inexpensive from a compute standpoint. However, business changes completely when an LLM has to start generating half a page of tokens in response to a query, which involves heavy compute and additionally which has to run on dedicated AI accelerators as opposed to vanilla CPUs.
At the same time, it’s not clear whether search via generative AI can be monetized to the same extent as traditional search, where you can get four to ten paid links on top and to the right of the ten blue links retrieved by the database lookup. While I’m positive that thanks to generative AI more search queries will happen as you’re getting better answers, this doesn’t necessarily mean that these can be monetized via ads. Most searches actually won’t be monetized, it’s only when you do specific searches to buy a product or book a holiday that Google can really make money. However, if you’re Googling to learn about history or any other random topic, there are no bucks to be made here. This probably means that a subscription model makes more sense for users who want continuous access to advanced generative AI. While at the same time, you want to limit making use of expensive generative AI in free searches to only those where it makes sense. This is Google’s CEO on some of these topics:
“We offer an industry-leading portfolio of NVIDIA GPUs along with our TPUs. We have developed new AI models and algorithms that are more than 100x more efficient than they were 18 months ago. Our custom TPUs, now in their fifth generation, are powering the next generation of ambitious AI projects. Gemini was trained on and is served using TPUs. We also announced Axion, our new Google designed and Arm-based CPU. In benchmark testing, it has performed up to 50% better than comparable x86-based systems.
For nearly a year, we've been experimenting with SGE (search generative experience) in labs across a wide range of queries and now we are starting to bring AI overviews to the main Search results page. We are being measured in how we do this, focusing on areas where gen AI can improve the search experience while also prioritizing traffic to websites and merchants. We have already served billions of queries with our generative AI features. Most notably, based on our testing, we are encouraged that we are seeing an increase in search usage among people who use the new AI overviews as well as increased user satisfaction with the results. Since introducing SGE about a year ago, machine costs associated with responses have decreased 80% from when first introduced driven by hardware, engineering and technical breakthroughs. We have clear paths to AI monetization through Ads and Cloud as well as subscriptions.”
Hyperscalers are building out their platforms to make it easy for customers to deploy and manage their machine learning projects. This is also known as Platform-as-a-Service (PaaS) as opposed to the more classic provision of pure servers, networking and storage over the cloud i.e. Infrastructure-as-a-Service (IaaS). This is Amazon’s CEO on AWS’ SageMaker platform to train models and their BedRock service to deploy and finetune LLMs:
“Companies are also starting to talk about the eye-opening results they're getting using SageMaker. Our managed end-to-end service has been a game changer for developers in preparing their data for AI, training models faster, lowering inference latency and improving developer productivity. Perplexity.ai trains models 40% faster and Workday reduces inference latency by 80% with SageMaker, and we see an increasing number of model builders standardizing on SageMaker.
The middle layer of the stack is for developers and companies who prefer not to build models from scratch but rather seek to leverage an existing large language model, customize it with their own data and have the easiest and best features available to deploy gen AI apps. This is why we built Amazon Bedrock, which not only has the broadest selection of LLMs available to customers but also retrieval augmented generation, or RAG, to expand a model's knowledge base, agents to complete multi-step tasks, and fine-tuning to keep teaching models. Bedrock already has tens of thousands of customers, including adidas, New York Stock Exchange, Pfizer, Ryanair and Toyota.”
Google has a comprehensive cloud platform as well and for startups it makes a lot of sense to start building on GCP as the platform is very developer friendly, i.e. it has great documentation, data management systems and machine learning services over API. In the meanwhile the company has also become a force in cybersecurity, with the company’s leading threat intelligence business, Mandiant. This is Google’ CEO giving some further details:
“Our differentiation in Cloud begins with our AI hypercomputer, which provides efficient and cost-effective infrastructure to train and serve models. Today, more than 60% of funded gen AI startups and nearly 90% of gen AI unicorns are Google Cloud customers, and customers like PayPal and Kakao Brain are choosing our infrastructure.
Our Cloud business is now widely seen as the leader in cybersecurity. I saw this first hand when I went to the Munich Security Conference in February. Cybersecurity analysts are using Gemini to help spot threats, summarize intelligence and take action against attacks, helping companies aggregate and analyze security data in seconds instead of days.”
Microsoft Azure is extremely strong in the enterprise market, on the recent call Satya Nadella noted that 65% of the Fortune 500 is now using Azure’s OpenAI service. Microsoft has a very similar strategy to both AWS and Google in that they’re offering Nvidia GPUs while at the same time they’re busy developing their own custom silicon.
At the same time, Microsoft has been building out a better set of data management systems, something which Google historically has excelled at. First Cosmos was launched, an extremely comprehensive NoSQL database which can compete with the likes of MongoDB, Cassandra, Amazon DynamoDB and Google’s Cloud Datastore. Now Microsoft is also moving into data warehousing and data lakes with the launch of Fabric, basically to compete with the likes of Snowflake, Databricks and Google BigQuery. This is Nadella discussing Fabric:
“Fabric now has over 11,000 paid customers, including leaders in every industry from ABB, EDP, Equinor, Foot Locker, ITOCHU and Lumen, and we are seeing increased usage intensity. Fabric is seamlessly integrated with Azure AI Studio, meaning customers can run models against enterprise data that's consolidated in Fabric's multi-cloud data lake, OneLake. Power BI, which is also natively integrated with Fabric, provides business users with AI-powered insights.”
An overview of Microsoft’s data lake, notice the similarities with Databricks and Snowflake:

These three large public clouds have a strong advantage in attracting AI workloads as enterprises are already running most of their cloud projects in either AWS, Azure or GCP anyways. This means that they have a lot of data and apps in these datacenters already, while their cloud engineering workforce is highly trained to work on these platforms, not only from the browser provided dashboard but also from the more typical command line as well as from making API calls in code. Typically a cloud engineer is highly trained on only one of these platforms, so someone is either an AWS, Azure or GCP specialist. This is why smaller platforms such as CoreWeave are at a strong competitive disadvantage, cloud engineers will have to be retrained, companies have to move their data and potentially apps, change their codebases etcetera. It’s a mess and basically you will only opt for these smaller platforms if you’re compelled to do so, for example, you might do your training workloads on CoreWeave if it’s much cheaper. At the same time, it’s likely you’ll want to run your inferencing alongside your other apps to reduce latencies, meaning that you will do this on one of the big three platforms. Needless to say, the large public clouds are extremely good businesses with strong pricing power.
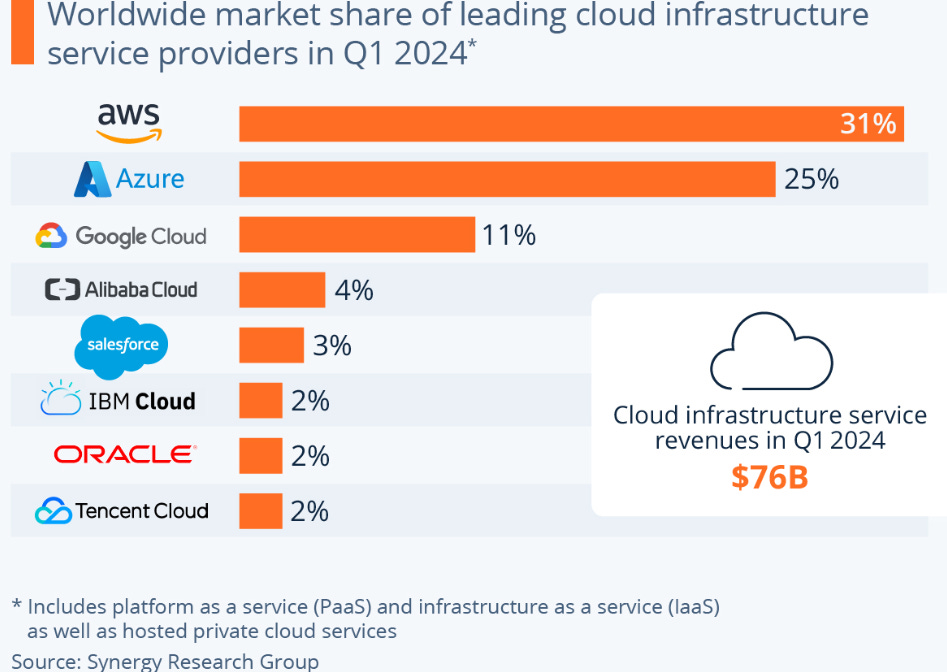
Hyperscalers have been stepping up capex and are signalling for this to continue. This is again Amazon’s CEO:
“We expect the combination of AWS' reaccelerating growth and high demand for gen AI to meaningfully increase year-over-year capital expenditures in 2024. The more demand AWS has, the more we have to procure new data centers, power and hardware. And as a reminder, we spend most of the capital upfront but as you've seen over the last several years, we make that up in operating margin and free cash flow down the road. We remain very bullish on AWS, we're at a $100 billion-plus annualized revenue run rate, yet 85% or more of the global IT spend remains on-premises. And this is before you even calculate gen AI, most of which will be created over the next 10 to 20 years from scratch and on the cloud. We are seeing strong demand signals from our customers, longer deals and larger commitments, many with generative AI components.
We have a multi-billion dollar revenue run rate in AI already and it's still relatively early days. At a high level, there's a few things that's driving that growth. First of all, there are so many companies that are still building their models. Once you get those models into production, when you think about how many generative AI applications will be out there over time, this is when you see the significant run rates. You spend much more in inference than you do in training because you train only periodically, but you're spinning out predictions and inferences all the time. And then you layer on top of that the fact that so many companies, their models and AI applications are going to have their most sensitive assets and data. It's going to matter a lot to them what kind of security they get and yes, if you just pay attention to what's been happening over the last year or two, not all the providers have the same track record.”
With the last comments he was obviously taking a few jabs at Microsoft which had some of their email services hacked on two occasions over the past years, once allegedly by a Russian hacking group and once by a Chinese one. Whereas last year’s theme on hyperscaler conference calls was one of a focus on customer cost optimizations, we’re clearly now seeing a shift on calls towards a bullishness on AI demand. Amazon for example flagged customer cost optimizations to be now largely behind them, mentioning that customers have learned a lot already over the past year how to run their operations more efficiently on the cloud.
An overview of capex growth rates in the hyperscaler market are shown below. Note that while Meta’s overall capex is down year over year, underneath there has been a large mix shift from other projects into AI activities and Zuck recently flagged to increase investments over the coming years.
The most important conclusion for leading edge semiconductors from this is that the public clouds’ bullish outlook and step ups in capex should form an attractive growth driver for the semiconductor value chain in the coming years. However, the public clouds themselves should continue to be attractive investments in the tech space as well. These are probably among the safest assets in tech, as customers are heavily locked-in into their platforms while having to pay subscription fees subject to price increases.
Amazon is the better pure-play in the public cloud, with currently 61% of profits streaming from this business. Microsoft is really a diversified portfolio of high quality tech businesses stretching from Windows and Office to business software, gaming and the cloud. Cloud exposure for Google on the other hand remains limited, and even more so in terms of profitability.
Amazon is currently trading on 39x forward EPS, with consensus projecting high twenties EPS growth rates in the coming years. Not a cheap stock but this remains a high quality and growth asset where I suspect that long term investors will continue to do well in this name.
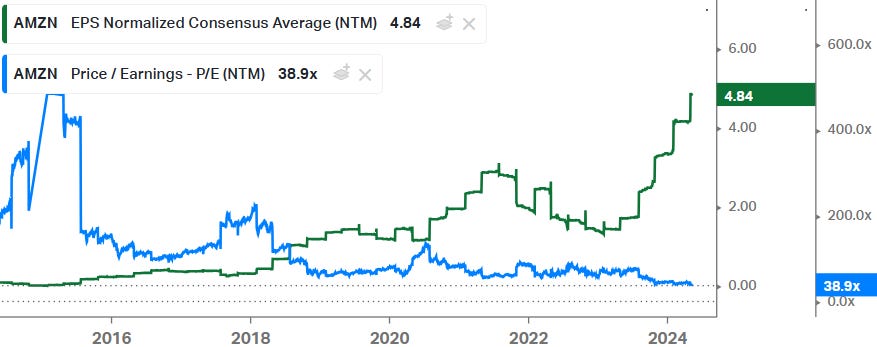
Microsoft is trading on 32x forward EPS but the company is projected to have lower EPS growth rates versus Amazon in the coming years, growing at around mid teens levels. The conclusion is the same as for Amazon really, obviously these shares aren’t a bargain here but it should be an extremely safe asset in tech which can bring in attractive growth rates.
KLA signals a semicap ramp
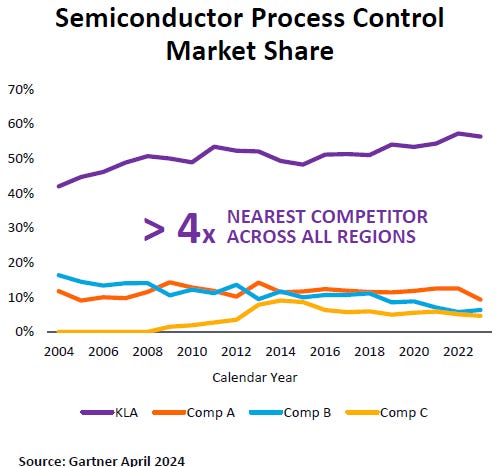
KLA is the strongest player in semiconductor process control, with tools typically seeing highest insertions in manufacturing lines when new process technologies are ramping up, continuously wafer quality.
An example of one of their tools:

Semicap has been in a downturn post the covid semi boom, however, with logic customers gearing up for the battle at 2nm in ‘25 and with memory customers ramping up HBM capacity, KLA is seeing now a strong demand picture next year:
“We are having different kinds of discussions now than we've had for a while with our leading-edge logic and memory customers. As they prepare for the ramp and are seeing increased demand, they're talking about tool availability, scheduling of resources and making sure that they don't get behind. We see stability with rising demand through the year, but the real build-out is going to come in '25 and beyond that. So we have really good leading indicators, design starts, advanced node discussions and R&D work.”
The company signalled 2026 to be probably even bigger than 2025. Currently, China is driving a lot of revenues with a huge amount of mature fab capacity being installed in the country. At the same time, Chinese semi manufacturers are sneaking in advanced, non-EUV fabs with the goal of having sufficient 5 and 7nm logic capacity. As such, currently the country is contributing 42% to KLA’s revenues. Chinese demand weakening or alternatively, additional sanctions being introduced by the US, are two risk factors that could cause weakening revenues for KLA before the coming semicap ramp. However, for the moment, KLA is seeing Chinese demand continuing to be healthy throughout the year.
Semicap should continue to be a good place for investors in the coming years. Not only do we get increased demand in the coming years coming from AI together with technology transitions in logic, DRAM and HBM; but also each geopolitical power has a desire to see advanced fabs being installed on their soil, from the US to Europe, Japan, South-Korea, Taiwan and China.
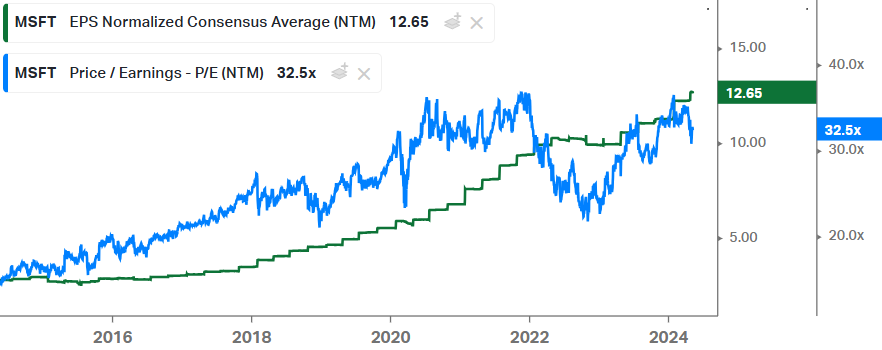
KLA is naturally a good name in this space, however, as with the rest of the semicap, we’ve seen a strong re-rating in multiples over the years. One used to be able to buy these types of stocks on 15x forward EPS, whereas now you have to pay multiples such as 27x in the case of KLA:
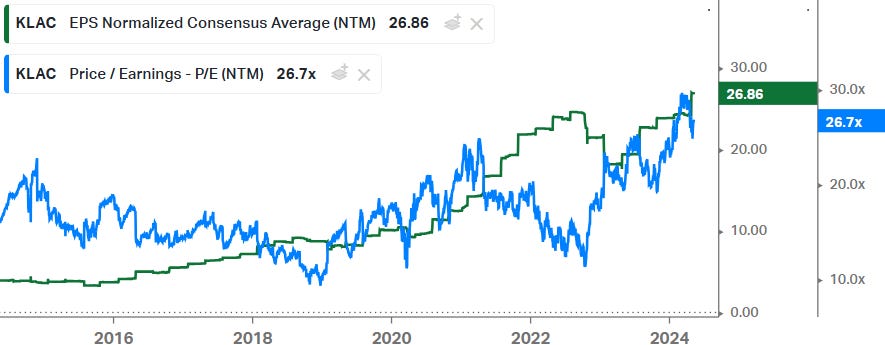
Some of this is justified, we should be heading into a very strong fab investment cycle while KLA is targeting an annual 10% top line growth rate through the cycle. However, long term, multiples are likely to come down again to more reasonable levels which is always good to keep in mind. The other point to note is that most of the semicap names are plays on Moore’s law as process technology transitions are a big driver of demand, whereas more generalist investors might assume that all demand is coming from fab capacity expansions.
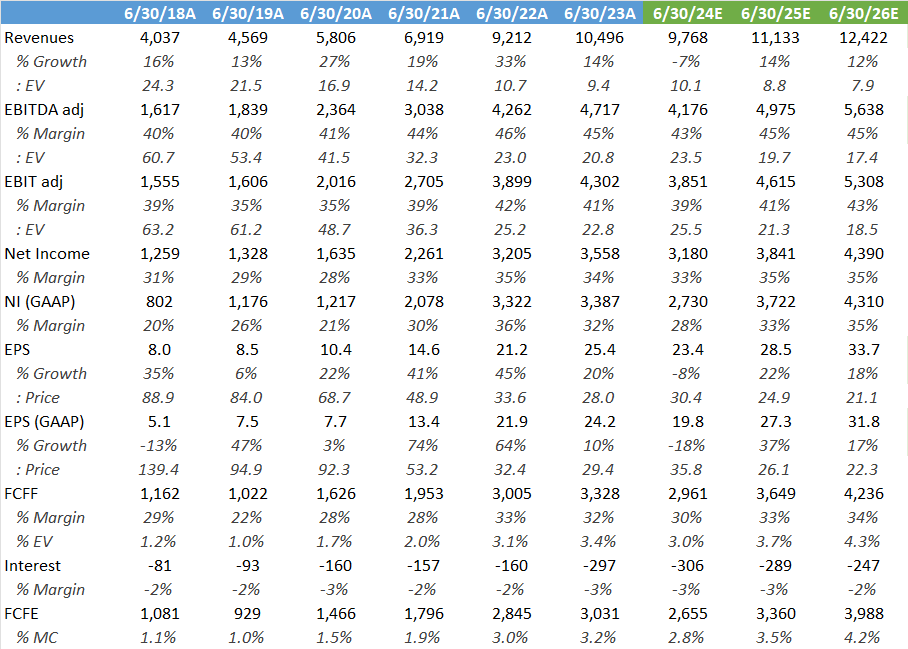
Financial accounts and estimates for KLA are highlighted below. Note the historically strong performance of this company, clearly this is a very well managed business.
AMD’s large opportunity no one is talking about
AMD has morphed into a diversified semiconductor titan, competing as a key player in a wide variety of end markets. But essentially, the three types of semiconductors the company sells are CPUs, FPGAs and GPUs:

Contrary to popular belief, AMD’s best quality business in my view is FPGAs. High-end FPGAs are essentially a two player market between AMD’s Xilinx and Intel’s Altera, and this is clearly reflected in margins on the chart below. Obviously client and gaming are the most competitive markets, although client margins reached excellent levels during the covid semi boom as customers rushed to buy PCs and GPUs over the lockdowns:
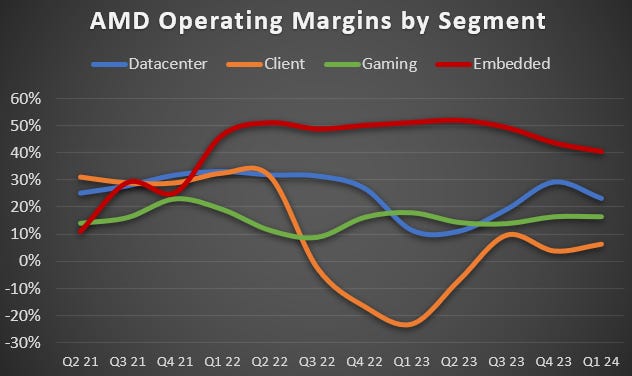
Datacenter margins are decent as well and this business has been a strong growth driver for the company over the years, as AMD took share from Intel which was struggling on all fronts. On the chart below you can see that, thanks to the datacenter market coming back with the AI semi boom and in combination with AMD successfully launching their MI300 GPU series, this basically saved the profitability of the company over the previous two quarters as industrial FPGAs (embedded) went into a cyclical downturn. In essence, with the shortages Nvidia has been facing, a few crumbs fell from Jensen’s table and AMD was able to print positive numbers over the last two quarters:
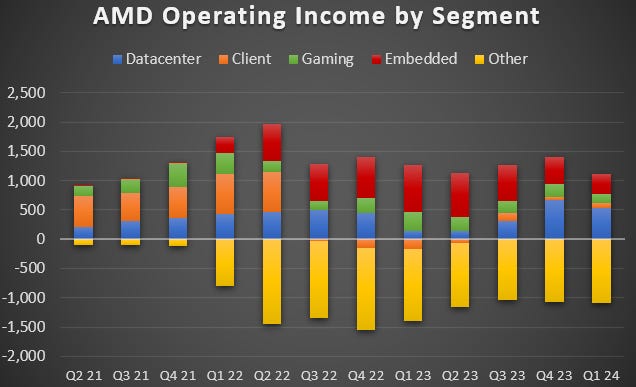
That being said, AMD is doing the right things in AI GPUs, they are building a roadmap to launch new products with the MI350 rumoured to be coming later this year. At the same time, the company is developing a software ecosystem to make it easy to train and deploy AI models on their GPUs. This is Lisa Su updating us on their efforts:
“On the AI software front, we made excellent progress adding upstream support for AMD hardware in the openAI Triton compiler, making it even easier to develop highly performant AI software for AMD platforms. We also released a major update to our ROCm software stack that expands support for open source libraries, including vLLM and Jax, and significantly increases generative AI performance by integrating advanced attention algorithm support for sparsity and FPA (fixed point arithmetic). Our partners are seeing very strong performance in their AI workloads. As we jointly optimize for their models, MI300X GPUs are delivering leadership inferencing performance and substantial TCO advantages compared to H100. For instance, several of our partners are seeing significant increases in tokens per second when running their flagship LLMs on MI300X compared to H100.”
Comparing performance to Nvidia’s H100 is starting to get stale as Jensen is now delivering H200 systems with additional HBM. Customers get 141 GB of HBM3E per GPU instead of the previous 80 GB of HBM3 with the H100. At the same time, clients are preparing to deploy B100s later in the year. Nvidia is not only an extremely fast moving target in GPUs to catch up with, but the company also has their vast AI ecosystem in place to deploy datacenters, from software libraries to networking and even complete GPU racks. And on all of this the company is rapidly innovating with a $10 billion annual R&D budget.

As a positive for AMD, AI inference will be the far larger market and as much smaller GPU clusters can be deployed here, this opens the door to get a foothold in this market. It is rumoured that the company will launch an updated MI350 GPU later in the year, making the move to TSMC’s 4nm node with added HBM. For comparison, Nvidia’s B100 will be manufactured on TSMC’s high-performance N4P node. However, it’s always good to keep in mind this is not purely about the number of transistors on a chip. What are even more important factors are the design of the chip and the efficiency of the C++ code running it. A software update can give a major performance boost to a GPU or other chips more generally.
So long term AMD definitely should be in a good position to start taking share of the inference market. However, as noted above, the hyperscalers are extremely keen to deploy their own custom accelerators and are working with the likes of Broadcom and Marvell in developing these. Needless to say, all this competition will be extremely attractive for TSMC who is the key foundry manufacturing all these chips. In the meanwhile, AMD keeps feasting on crumbs falling from Jensen’s table, as the company is guiding for $4 billion of datacenter GPU revenues this year which compares to the $100 billion Nvidia will likely do. Clearly AI remains the Nvidia show for the moment and this will likely remain to be the case in the coming years.
The other important business for AMD is embedded, which is now going through a cyclical correction. CEO Su however flagged that we should be bottoming currently with growth picking up in the second half of this year. Additionally, FPGAs should benefit from a long term growth driver in the form of AI, as more models and automation are being deployed at the edge. This is also an opportunity which Microchip and Lattice have been talking about, two companies which are competing in the mid-range FPGA market.
FPGAs are typically used on the edge for smaller AI tasks such as processing video, audio and other sensory data. These chips can do this with low latency and high power efficiency while allowing for reprogramming at any time, giving chip designers high flexibility to change AI algorithms later on. So as ever more automation is being introduced in the real physical world with drones, robotics, security cameras and autonomous vehicles, FPGAs are in a great spot to benefit from this trend.
This is Lisa Su on the outlook for this business:
“Turning to our Embedded segment. Revenue decreased 46% year-over-year and 20% sequentially as customers remain focused on normalizing their inventory levels. We launched our Spartan UltraScale+ FPGA family with high I/O counts, power efficiency and state-of-the-art security features, and we're seeing a strong pipeline of growth for our cost-optimized embedded portfolio across multiple markets. Given the current embedded market conditions, we're now expecting second quarter segment revenue to be flat sequentially, with a gradual recovery in the second half of the year.
Longer term, we see AI at the edge as a large growth opportunity that will drive increased demand for compute across a wide range of devices. To address this demand, we announced our second generation of Versal adaptive SoCs that deliver a 3x increase in AI TOPS per watt and a 10x greater scaler compute performance compared to our prior generation of adaptive SoCs.
Versal Gen 2 adaptive SoCs are the only solution that combine multiple compute engines to handle AI pre-processing, inferencing and post processing on a single chip, enabling customers to rapidly add highly performant and efficient AI capabilities to a broad range of products. We were pleased to be joined at our launch by Subaru, who announced they adopted Versal AI Edge series Gen 2 devices to power the next generation of their EyeSight ADAS system.”

Lastly, we arrive at the datacenter CPU business which is somewhat less important currently as all of the growth in datacenter spend is in the GPU ecosystem. Nevertheless, AMD commented that they again took some share from Intel in what was a flat Q1. However, in the near future as Intel becomes more competitive again with TSMC with Intel’s 18A node ramping up, market share gains for AMD in this business should become less easy.
Looking at valuation, if the company can hit consensus numbers, we’re looking at a 3% FCF yield in ‘25. This remains fairly attractive if the business can grow their top line at annual rates in the high tens to low twenties, combined with 30%+ annual EPS growth.
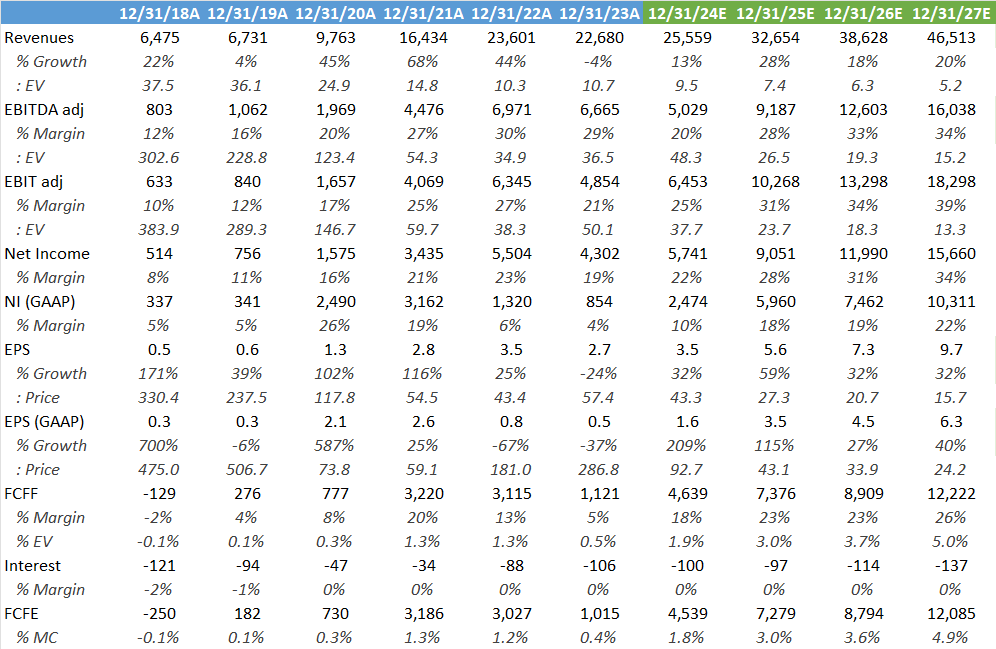
Forward EPS has been fairly stagnant over the last two years and compared to history, the current valuation isn’t bad, you’re basically paying the average multiple of the last five years:
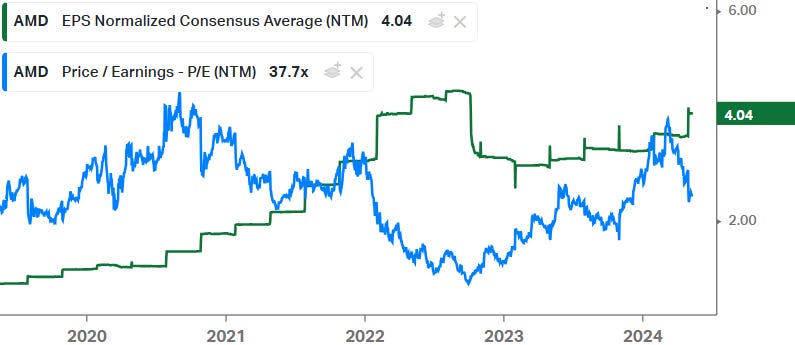
Overall, AMD is really a mixed bag. I wouldn’t buy that CPU business standalone as in my opinion this is becoming an overly competitive market. On the plus side though, we might see a strong upgrade cycle in business PCs to run smaller and dedicated language models on integrated NPUs (neural processing units). Similarly, I suspect AI in the datacenter will remain the Nvidia show in the coming years. Although I can see AMD longer term definitely getting a decent foothold in the inferencing market. The business I like best are FPGAs, this is an attractive duopoly and if edge AI can become a strong growth driver, over time this could actually become the biggest story for AMD. While no one is really talking about this currently.
If you enjoy research like this, hit the like and restack buttons, and subscribe if you haven’t done so yet. Also, please share a link to this post on social media or with others who might be interested, it will help the newsletter to grow, which is a good incentive to publish more.
I’m also regularly discussing tech stocks on my Twitter.
Disclaimer - This article is not a recommendation to buy or sell the mentioned securities, it is purely for informational purposes. While I’ve aimed to use accurate and reliable information in writing this, it can not be guaranteed that all information used is of this nature. Before making any investment, it is recommended to do your own due diligence.