
The AI datacenter, Nvidia's integrated AI factory vs Broadcom's open fabric
Outlook post Nvidia's and Broadcom's AI events

Both Nvidia and Broadcom held their respective AI events last week, presenting two opposing viewpoints for the future of the AI datacenter. The former’s strategy is really to have customers run all their AI workloads on Nvidia’s vertically integrated solution, from the company’s GPUs and now also CPUs, to Nvidia’s server racks and networking, all powered by Nvidia software and libraries. The company has been building up an impressive software ecosystem over the years. Most famous is its CUDA GPU computing platform, allowing for the hyperfast general purpose programming languages C and C++ to execute on any of Nvidia’s GPUs, avoiding the need for cumbersome graphic programming techniques. Additionally, AI engineers get access to a wide variety of libraries to deploy and scale workloads on Nvidia GPUs. For example, data processing with Python pandas can now be accelerated on the company’s GPUs and Nvidia also offers inferencing libraries such as TensorRT-LLM and Triton Server to deploy trained AI models on Nvidia GPUs. These AI models can be developed with popular frameworks such as Pytorch and Tensorflow.
A lot of financial analysts have the impression that AI coding is happening in CUDA, which would give Nvidia a strong moat on the software side, but this is unfortunately not the case. Practically all AI code is written in Pytorch, which can run on top of CUDA, CPUs, and now also increasingly on AMD’s ROCm GPU computing platform. If you want to run a Pytorch model on another GPU, you have to use a compiler provided by the manufacturer or alternatively, write your own. Both Pytorch and Hugging Face, i.e. the community to share AI models, are very motivated to extend support for ROCm and other GPU computing platforms as they don’t want the future of AI to be controlled by a single manufacturer. So why is everyone then still buying Nvidia GPUs if we can now run our Pytorch model over AMD GPUs as well? Well, we’ll go into this later, but Nvidia’s GPUs are simply still way better at running workloads. Additionally, as LLMs have to be deployed over multiple GPUs, Nvidia has both the networking hardware and software libraries to easily do this both in training and inferencing. So CUDA won’t be a sufficient moat in the long term to stay ahead of competition. In my view, what Nvidia really needs is a fast pace of innovation in the AI ecosystem, both on the software and the hardware sides. The company is now spending $8 billion annually in R&D to advance the Nvidia ecosystem both on the hardware and software sides, and there will be very few players in the world who will have both this budget as well as the required know-how and expertise to even have a chance of competing with this.
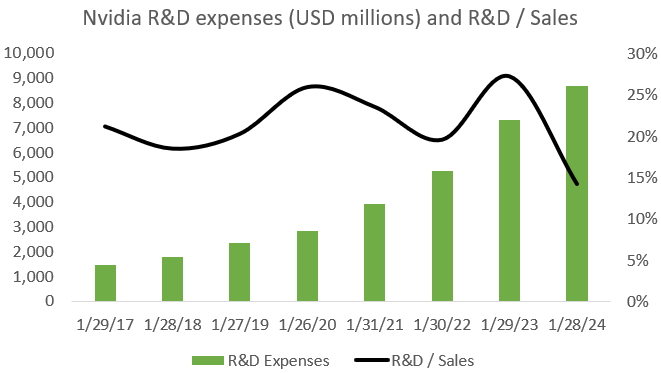
If the pace of innovation slows down, it will be easier for competition to narrow the gap. For example, if the evolution in LLM architectures becomes predictable, hyperscalers will be in a strong position to offer custom silicon to address these workloads. Similarly, if Moore’s law and more-than-Moore technologies start proceeding at a slower cadence, competitors and hyperscalers can more easily build out their ecosystem of competing hardware and accompanying software libraries.
A final moat for Nvidia is that the company is moving ever deeper into the AI training stage, where the goal of its Omniverse software platform is to provide a physics-enabled virtual environment for AI training. This is particularly useful for reinforcement learning type tasks, Mercedes has been training their autonomous driving system in Omniverse for example. So you can integrate the latest AI transformer technology in your models for example and then improve it further via reinforcement learning inside Omniverse. Both robotaxis and humanoid robotics could become vast markets in a decade or so, and as Nvidia both provides the physics training ground combined with the GPU platform that goes inside of the robotaxi or robot, the company is in a good position to play an important role in this value chain.
The opposing view for the future of the AI datacenter was provided by Broadcom. Rather than having everything vertically integrated, Broadcom is seeing a plug and play world, where components of different manufacturers can be swapped in and out of the AI datacenter at will from GPUs to CPUs, NICs and switches, communicating over open standard ethernet. The AI compute world Broadcom is seeing will be running on lower power custom silicon, also commonly known as ASICs, as opposed to Nvidia’s higher power general purpose datacenter GPUs. As training compute has been rising at a rate of 100x every two years (chart below, note the log scale), the argument for power efficiency is an important one:
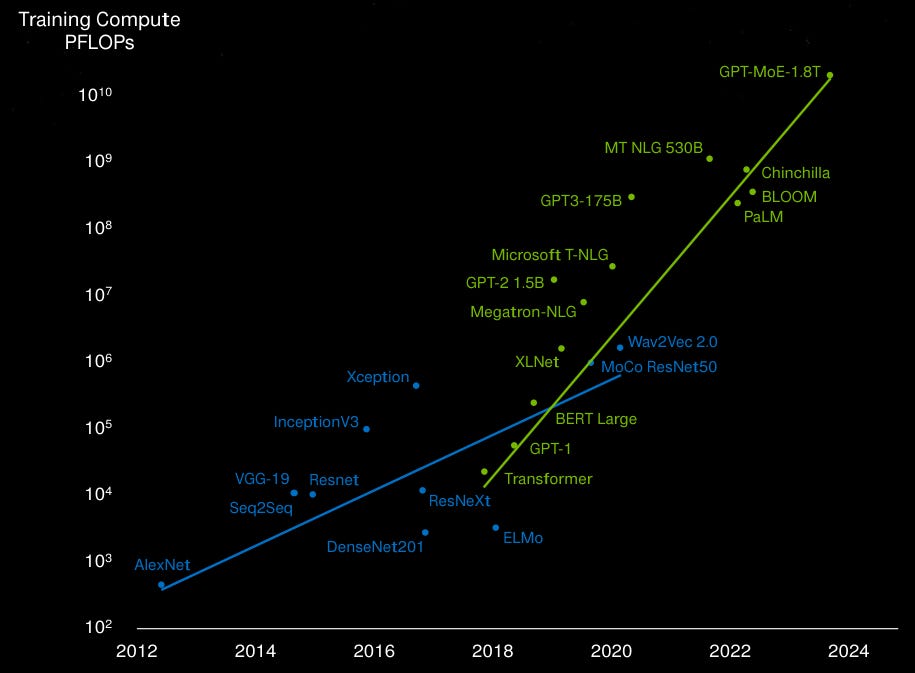
So whereas Nvidia has more an Apple or Tesla-like approach, i.e. hardcore engineering combined with vertical integration to provide the best customer experience, Broadcom is seeing more an Android smartphone or Windows PC world for AI, i.e. software platforms running on hardware from any manufacturer. Now, both of these models have long and successful histories in tech as both have certain advantages. Vertical integration in the case of the Apple model and specialization for the Android model, i.e. every player in the value chain is focused on his task.
In this post, we’ll dive into both companies’ AI datacenter technologies and we’ll also do a financial analysis for both at the end. We’ll start with Broadcom as they provided a lot of detail on the lower level chip technologies powering the datacenter, before going into Nvidia’s more holistic and vertically integrated approach.
Broadcom’s open fabric AI datacenter
Broadcom’s COO started the AI event by moving away from the term GPU, which is the name popularized by Nvidia, while at the same time laying out the case for custom silicon:
“The AI accelerator, many people call it GPUs, some call it TPUs and others call it NPUs. For today, let's refer to it as XPUs. There are 2 ways you actually can develop these products. One, you can develop a general product that fits everybody's needs, which is great. However, if you're a consumer AI company and you're building these large-scale platforms, these general processors are actually too powerful in terms of power consumption and too expensive to deploy into their networks. Some of them have no choice today because they don't have the ability to do a custom capability. But the few that have the scale of billions of users, generating over $0.5 trillion in revenue, have that capability. And that's why we coin custom XPU or custom AI accelerator.”
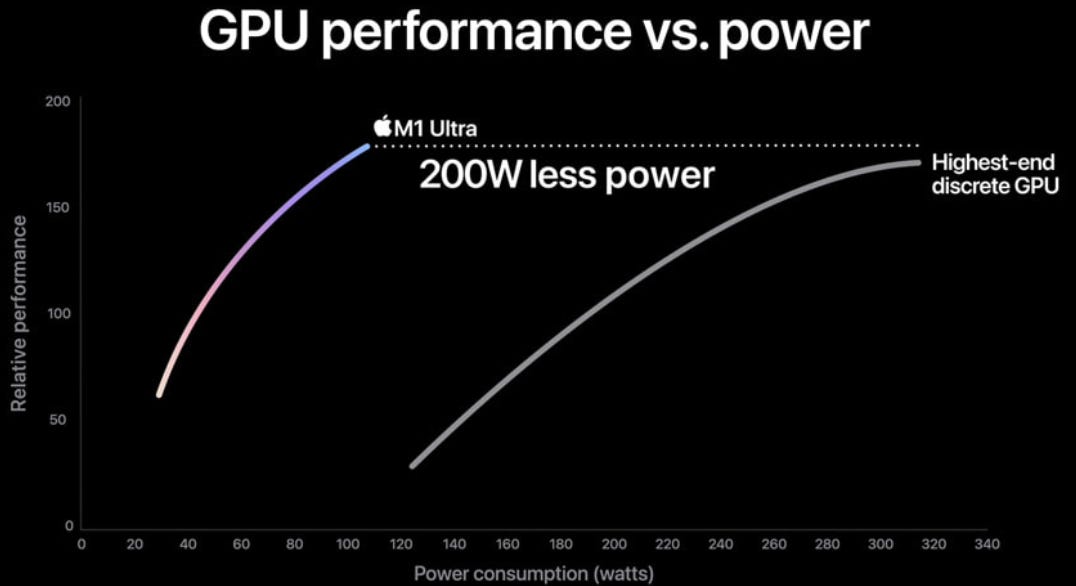
The company has three large customers now for their custom GPU business, it is well known that Google’s TPUs were the first, I’m guessing that Microsoft is the second one, and recently it has been speculated that either Meta or Bytedance would be the third. If my memory serves me well, Amazon would be working with Broadcom’s competitor Marvell. Designing these leading edge GPUs is an extremely R&D intensive business, with costs going into the billions of dollars. Nvidia mentioned they spent $10 billion on developing the overall Blackwell platform, more on this later. A lot of know-how and expertise are required, so this should be a good business with high barriers to entry. The main risk for both Broadcom and Marvell in this business would be that the internet and cloud giants start insourcing these activities more in the future, similar to how Apple has been designing ever more of their silicon in-house. Apple illustrates how custom silicon gives them performance benefits:
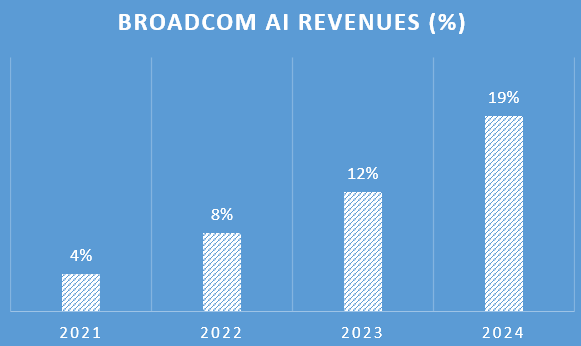
As also Broadcom is the strong player in both networking and other datacenter technologies such as connectivity — together with Marvell again — these AI datacenter revenue streams would start contributing 19% to Broadcom’s revenues this year:
This is Broadcom’s COO laying out the huge AI bull case for semiconductor investors, they’re talking with customers on how to build one million GPU AI clusters:
“If we go back to 2 years ago, a cluster that was state-of-the-art at the time had 4,096 XPUs, each XPU was a couple of hundred watts, and to interconnect 4,000 of these was fairly simple with a single-layer networking layer using our Tomahawk switches. In 2023, we actually built a cluster that is over 10,000 nodes of XPUs and it requires 2 layers of Tomahawk or Jericho switches. And this is the lowest power XPU in the industry today, less than 600 watts and using the latest technology. Now as you go towards 2024, we are going to extend this to over 30,000 and the objective of many of these consumer AI customers is how do we take this to 1 million.”
Here we get an overview of the key semiconductors involved in building these AI clusters:
“So a cluster starts with an XPU. Typically, there's 8 of them in a server, unless you use Broadcom custom XPUs, you can have 12 or 24 of them. Because when you customize it, you can actually significantly cut the size and power. You have to connect these processors together and that function is called scaling up. That can be done through a PCIe switch, a proprietary switch, or even an ethernet switch. After that, you bring x86 or ARM processors as the control plane and that interconnect is done through PCIe switches. To get these to exit the server, you need network interface cards (NICs). So the basic building block is called the AI server or the AI node.
Now we have to take many of these servers and scale it out. That's the next step of architecting a cluster. You're going to have to use the best networking technology and we believe that the best networking technology is ethernet. As you scale up typically in 10,000 or 30,000 nodes, you need at least 2 layers of leaf and spine. And to do that, you need top of rack switches and spine switches, that's called the front end. Once you do that, you need to interconnect all of these with our optics products.
Remember the lowest power XPU today is ours, that's about 600 watts and the next one would be in the range of probably 1,000 watts. If you want to do 30,000 of these in a cluster, just the XPUs will use 30 megawatts of power. Most data centers, that's the maximum power they can give you. To solve this, we believe that this important inflection point in the industry has to be driven by open standards like ethernet, PCIe and other standard capabilities at the memory level. As you move beyond 10,000 and 30,000 XPUs, it becomes a distributed computing challenge and this will be solved with the best networking architecture that will be out there. Lastly, but most importantly, we need power efficient technologies.”
So the key point here is that due to the power constraints of a typical datacenter, Broadcom is arguing that AI accelerators will have to transition to custom silicon. These are optimized for particular AI workloads, thereby bringing in lower power and size requirements. The other important factor from an investment standpoint is obviously that a lot of networking and connectivity technology is involved, from switches to PCIe, which is again an area Broadcom excels at.
Let’s first go further into the custom silicon business, this is Broadcom’s head of ASICs detailing this unit:
“In 2014, we met a customer that decided to do something really cool in AI, and we developed an AI chip for them. As such, we started shifting resources and focus on AI. The benefit of custom silicon can be explained by a simple equation: performance divided by the total cost of ownership. The total cost of ownership is the cost of the chip, plus the cost of the power, plus the cost of the infrastructure to put it together. When you are one of these large internet companies, you have internal workloads that are very important for your revenue generation and for your applications. So if you customize the architecture of your accelerator, your bandwidth, the right ratio of I/O and the right ratio of memory, you can do those specific workloads much more efficiently than on general hardware. We work with our customers to customize the architecture that they have, to make sure that they can maximize performance for what they care about. And there's another really good effect, which is when you optimize hardware, you make it smaller and you make it cheaper. The other benefit, when you optimize power, you are optimizing power costs.
Let’s touch on the different aspects of an XPU. Number one, compute. We have developed a flow to optimize the architectural construction of that compute. We have several software engineers in my team, all they do is optimize the flow to build those accelerators i.e. really small, really fast and improving the TCO. Number two, memory. This is the ability to have HBMs and other memory solutions that have the right size, connectivity, cooling and testing and we're running these interfaces significantly faster than any standard or any competitor out there. Number three, I/O. We have created software tools that allow us to put together chiplets with wider and thinner I/O, to match the exact type of precision and ratio that the customer wants for their workloads. So we can do a 200 gig or a 100 gig PCIe and if they need another one next time, we just change it and we can go to production quickly. And we can give that to the customer before production so they can emulate the chip, they can simulate and they can solve all the problems. Number four, packaging. We can do 2.5D, 3D and silicon photonics, which is really hard. With 10 years of designing these AI chips, we have learned both our mistakes and our customers’ mistakes, and we have coded in software all these solutions to make sure that we're like a machine, with a lot of discipline and with a lot of automation to avoid errors.”
Below are two examples of AI accelerators designed by Broadcom for the internet giants. Obviously these are very advanced chips, large die sizes with up to 110 billion transistors in one die, 2.5D interconnected with 128 GB of HBM and 6 TB of networking bandwidth. Basically it’s a module that’s comparable to Nvidia’s current flagship H100 GPU.
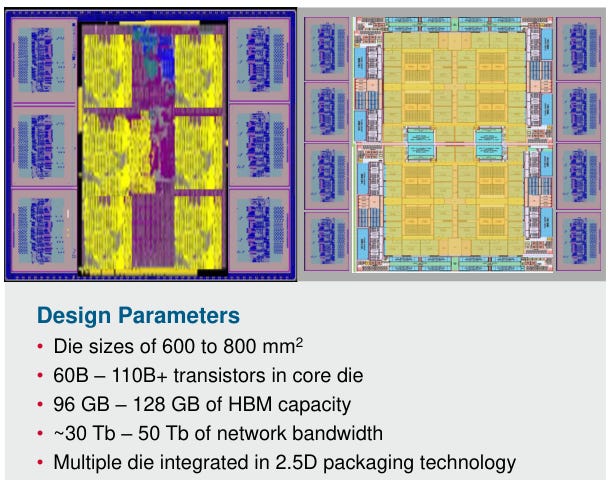
You can see that Broadcom has over 150 tape-outs at the foundries’ leading process technologies, including 10 tape-outs at the latest 3nm:
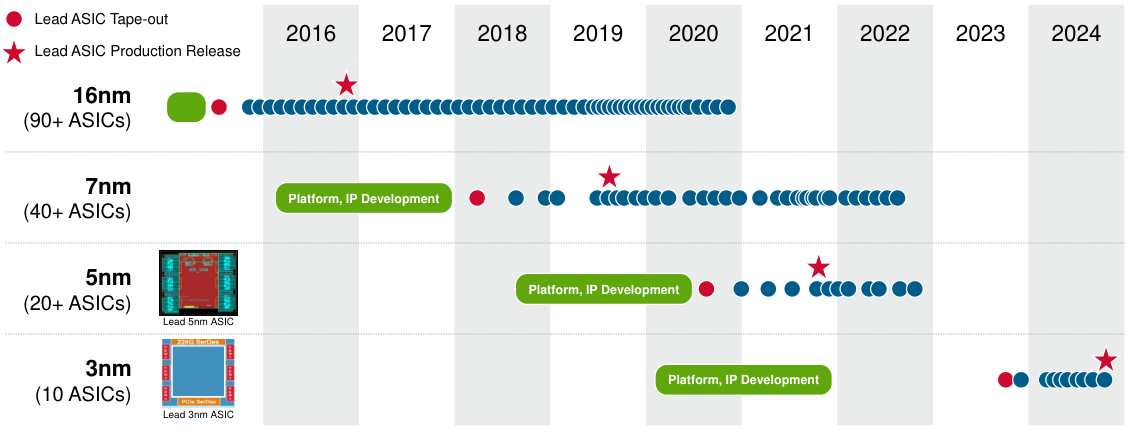
At the company’s ‘22 ASIC event, they mentioned that this business has been growing at a 20% revenue CAGR. Obviously this is an interesting business, and the company can leverage all their knowhow and expertise from designing state-of-the-art semis over the past decades. However, the attraction of optimizing for one workload is also its major drawback. The reason that Nvidia has a market share of over 80% in AI workloads is that their GPUs not only perform spectacularly well, but they do so on the widest variety of workloads. As long as the field of AI keeps rapidly evolving, it makes much more sense to simply install a Nvidia cluster. Not only is it easier to deploy all your AI code on this cluster, but it makes you better future proof as AI workloads keep evolving over the coming years.
A recent example of the MLPerf test illustrates this, Nvidia’s H100 trumped Intel’s Gaudi on all workloads, and in some quite spectacularly so:

The other interesting AI datacenter exposure for Broadcom is their strong positioning in networking. This is the company’s head of switches on their networking strategy:
“This is a picture of Google's cloud about 20 years ago, what you see here is a bunch of commodity servers. They didn't pick the highest performing CPU, they picked the CPU that offered the best cycles per given cost and they connected it over ethernet. So they built the world's largest distributed computing system extended between data centers. What Meta showed is when they are running large AI workloads, anywhere between 18% to 57% of the time the traffic is just sitting in the network. That means that the GPUs are sitting idle.
Here's how we solve this problem. We have our Jericho 3 AI chip in production now, and you can deploy large clusters of up to 32,000 GPUs. These chips, they're 800 millimeters square — the largest that you can build in a reticle — and they have multiple HBMs. This is the architecture that Meta actually just recently published in a paper. They compared 2 clusters, one cluster based on InfiniBand — because there's a raging debate that somehow InfiniBand is magical, other than the fact that it's super expensive — and the other on ethernet. So they ran 2 clusters of 24,000 GPUs each and they tested it. Ethernet works fine, it's half the price and it doesn't melt down, it's 10% better performance than other alternatives. If you have a $2 billion to $10 billion infrastructure, 10% is about anywhere from $200 million to $1 billion and I'd be lucky if I got paid that much for the network. So for every dollar I spend, I save $1 and more.
The second way we solve this problem, we have the Tomahawk class of devices. Every 18 to 24 months, we are doubling the bandwidth. We are never in the habit of announcing products before we ship. I have seen others who announced products 2 years ahead of us, and we are shipping a year ahead of them. To get the bandwidth between the GPU and the switch, you need a NIC. This is Thor 2, our performance NIC which basically means we're focused on bandwidth. So GPUs need a lot of bandwidth and the NIC has to keep up.”
So Broadcom mentioned the two main types of their network switches, Tomahawk and Jericho. Tomahawk is a top-of-rack switch, it provides very high bandwidth to the servers at low cost. Jericho on the other hand can be used as a spine switch, it provides deep buffers to handle unpredictable workloads coupled with advanced telemetry, so you can get insights into the traffic.
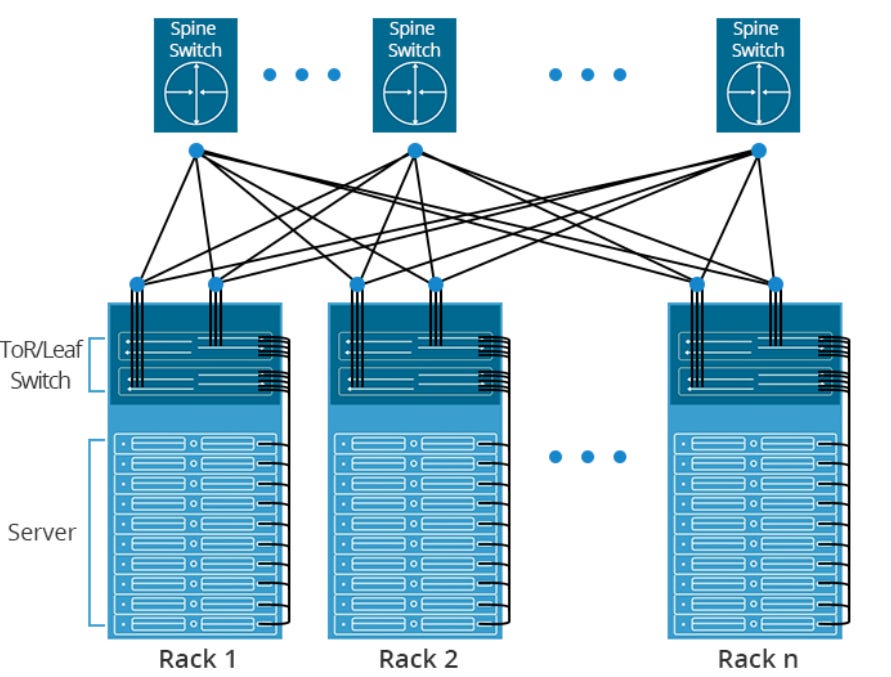
Broadcom did some bashing of Infiniband as this is the networking technology promoted by Nvidia. The drawback is indeed that infiniband is higher cost, but the attractions are that it is extremely low latency and offers high bandwidth, and is thus very attractive for both high-performance computing as well as AI applications. Nvidia has also been moving into ethernet with its Spectrum X-branded ethernet tech to offer the best of both worlds, i.e. low cost and ubiquitous ethernet in parts of the datacenter where it makes sense, such as where traffic is flowing in and out of the datacenter i.e. North-South traffic. And high performing Infiniband where you connect all the GPUs together i.e. the East-West datacenter traffic.
For premium subscribers, we’ll further dive into:
Broadcom’s datacenter business
Nvidia’s integrated AI factory
A financial analysis and thoughts on valuation for both Broadcom’s and Nvidia’s shares