
Snowflake vs Microsoft's Fabric, and AMD vs Nvidia at Computex
Tech thoughts

Snowflake vs Microsoft's Fabric
Snowflake had a good quarter, with Product Revenues slightly accelerating to a 34% growth rate, although the company had the benefit of a leap year here. Excluding the beneficial impact of the extra day, revenues continued to slightly decelerate to a 32% year-over-year growth rate:
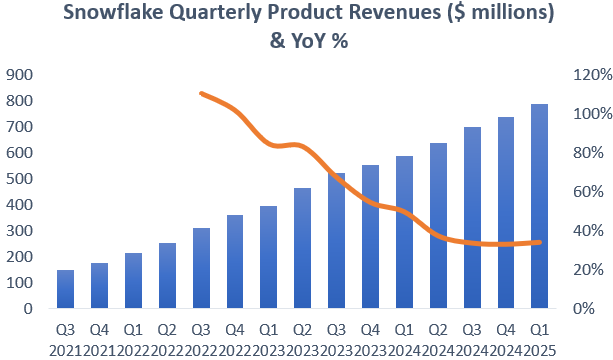
While we got a slight upgrade in the revenue guidance for fiscal year ‘25 of $50 million, the above path of decelerating revenue growth looks like its continuing, or at least for a while. We discussed last time why there are reasons for optimism and that it looks like the company is setting an overly prudent guide, one key reason being that the company is growing its long term contractual bookings at a much faster rate:
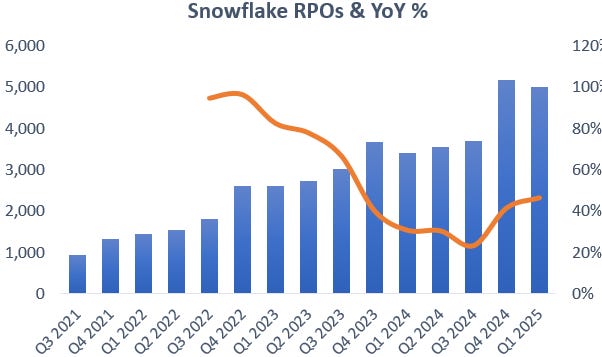
During the guide, it also became clear that Snowflake’s margins will be impacted by GPU investments, causing the shares to sell off with around 14% at the moment of writing. Now being a long term investor, I actually take the GPU investments as a positive — as this means that demand for Snowpark, Snowflake’s AI training platform should be strong — but I suspect that shorter term investors looking for EPS upgrades exited their position, the so called ‘hot money’.
This is Snowflake’s CFO on the results and outlook:
“Intra-quarter, we saw strong growth in February and March. Growth moderated in April and we view this variability as a normal component of the business. April, just as a reminder, really impacts Europe with Ascension Day or Easter holiday and they take a long time off. We continue to see signs of a stable optimization environment. Seven of our top 10 customers grew quarter-over-quarter.
Now let's turn to our outlook. As a reminder, we only forecast product revenue based on observed behavior. This means our FY '25 guidance includes contributions from Snowpark but it doesn't include revenue from newer features such as Cortex until we see material consumption. Iceberg will be GA (generally available) later this year. We have invested in Iceberg because we expect it to increase our future revenue opportunity, however, for the purpose of guidance, we continue to model revenue headwinds associated with the movement of data out of Snowflake and into Iceberg storage. The negative impact is weighted to the back half of the year.
We are increasing our FY '25 product revenue guidance, we now expect full year product revenue of approximately $3.3 billion, representing 24% year-over-year growth. Turning to margins. We are lowering our full year margin guidance in light of increased GPU-related costs with our AI initiatives. We are operating in a rapidly evolving market, and we view these investments as key to unlocking additional revenue opportunities in the future.
One of the cool things about our AI products is that our customers don't have to make big investments, they don't have to make commitments to how many GPUs that they are going to be renting. And this means that they can focus very much on value creation.”
So we have a reasonably modest 24% guided growth rate for the year while the demand for Snowflake’s platform should be in a goldilocks environment. After all, companies are looking to consolidate their data for AI training and applications, and naturally Snowflake’s data warehouse and data lake in the cloud are ideally positioned to take care of these types of workloads. This is Microsoft’s VP of Cloud AI at the recent JP Morgan conference discussing these trends:
“Customers are pivoting to intelligent app development with the onset of generative AI, how do you bring together disparate data sets and have an enterprise-wide data architecture. You migrate to innovate because your AI solution is only as good as your underlying data. That data has to be in a cloud-based environment and so you see organizations that are migrating their data to be able to apply the new AI services on it. We actually are seeing organizations start with the [Azure AI] API, bringing in their unstructured data into a blob storage type capacity, but then actually moving into more sophisticated analytical data services. Of the 53,000 Azure AI customers that I talked about, 1/3 of those are new to Azure but half of them are actually using our data services as well.”
The last few phrases offer another possible explanation for Snowflake’s tepid guide. Snowflake now has seen three credible competitors emerge. Firstly, there is Databricks, which comes from a machine learning background but has now also integrated data warehousing capabilities built-in into their cloud platform. Secondly, there is Google’s BigQuery, which is a longer established player in the big data analytics market and which has been upgrading its capabilities to compete with Snowflake. Lastly, there is the fast growing and leading public cloud Microsoft Azure, which introduced its cloud data analytics platform Fabric last year and which bears many architectural resemblances to both Databricks and Snowflake.
This is Microsoft’s CEO on the previous conference call:
“We are also encouraged by our momentum with our next-generation analytics platform, Microsoft Fabric. Fabric now has over 11,000 paid customers including leaders in every industry such as ABB, EDP, Energy Transfer, Equinor, Foot Locker, ITOCHU and Lumen, and we are seeing increased usage intensity. Fabric is seamlessly integrated with Azure AI Studio, meaning that customers can run models against enterprise data that's consolidated in Fabric's multi-cloud data lake, OneLake. Power BI, which is also natively integrated with Fabric, provides business users with AI-powered insights.”
So while both Snowflake and Databricks are claiming to win market share from each other, it is clear that the competitive environment for Snowflake has intensified over the last year with now also Microsoft emerging with a strong solution.
Under the leadership of Satya Nadella, Microsoft has really transformed from a dull company, which was even dumb enough to buy Nokia’s phone business, to one of the most exciting companies in tech. Similarly this was a company which was hated in the developer community but has now gathered a lot of sympathy by its moves toward open source software with VS Code and Linux on Windows. Obviously Nadella has done a tremendous job and we’ve discussed previously why the public clouds such as Amazon AWS and Microsoft Azure remain among the best quality assets in tech.

Snowflake remains well positioned, but whereas over the last decade they were a unique and disruptive cloud data warehouse with capabilities for unlimited data scaling, the market is now transitioning to one containing four strong players which can compete to move data analytics workloads over the cloud. Historically also AWS Redshift was a strong player, so don’t discount Amazon to make the necessary investments and stage a comeback in this area.
As a positive for Snowflake, customer uptake of Snowpark, the new integrated module for data science workloads, seems to be going very well. This is Snowflake’s CEO on Snowpark:
“More than 50% of customers are using Snowpark as of Q1 and revenue from Snowpark is driven by Spark migrations. In Q1, we began the process of migrating several large Global 2000 customers to Snowpark.
We are making meaningful progress on Snowpark Container Services being generally available in the second half of the year, and dozens of partners are already building solutions that will leverage container services to serve their end customers.
We announced support for unstructured data over two years ago. Now about 40% of our customers are processing unstructured data on Snowflake and we've added more than 1,000 customers in this category over the last 6 months.”
Spark is the engine used by Databricks for data science workloads, so Snowflake is commenting here to be winning business from them. Container services allow customers to run their own apps in Snowpark, a container is basically a lightweight and isolated virtual environment where you can deploy an app and the set of libraries it depends on. So all of this is about making Snowpark more versatile and developer friendly, while making it a great environment for data science engineers who like to write everything in Python or hardcore C++.
Similarly, unstructured data has traditionally been more the bread-and-butter of Databricks. But now Snowflake has been successfully moving into this area as well. However, note that Databricks is making similar comments. For example, they mentioned that they’ve been attracting traditional SQL-like data warehousing activities from Snowflake onto their data lake.
We’ve previously hypothesized that Snowflake’s data sharing capabilities can create a network effect around the platform, as related companies standardize on Snowflake to share data with each other. This thesis looks like it’s playing out. This is Snowflake’s CEO on collaboration trends over their platform:
“Our collaboration capability is also a key competitive advantage for us. Nearly one-third of our customers are sharing data products as of Q1 2025, up from 24% one year ago. Collaboration already serves as a vehicle for new customer acquisition. Through a strategic collaboration with Fiserv, Snowflake was chosen by more than 20 Fiserv financial institutions and merchant clients to enable secure direct access to their financial data and insights.”
Note also that Snowflake’s CFO was baking in for Iceberg tables to be a headwind to revenue growth. The main reason being that it also allows for data to be stored outside of the Snowflake platform, making the company miss out on these storage revenues. However, long term it should actually become a large revenue driver as there are plenty of companies which didn’t want to be locked in into Snowflake’s solution. So Iceberg is really meant to address this, by allowing these customers to store their data in any public cloud’s object storage, and then process the data over the Snowflake platform for business analytics or machine learning.
This is Snowflake’s CEO discussing this opportunity:
“Iceberg is enabling us to play offense and address a larger data footprint. Many of our largest customers have indicated that they will now leverage Snowflake for more workloads as a result of this functionality and more than 300 customers are using Iceberg in public preview.
The fact of the matter is that data lakes or cloud storage in general for most customers, has data that is often 100 or 200x the amount of data that is sitting inside Snowflake. And now with Iceberg as a format with our support for it, all of a sudden, you can run workloads with Snowflake directly on top of this data. And we don't have to wait for some future time in order to be able to pitch and win these use cases.”
On financials and valuation, as a result of the tepid guide and downgraded margins, the shares are now trading on their lowest multiple in history:
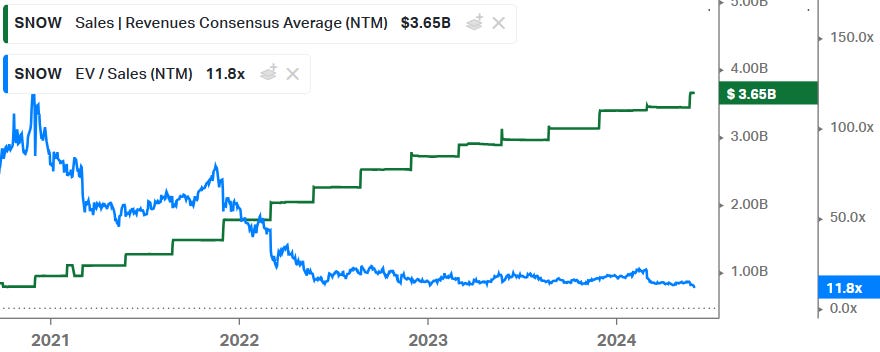
Consensus estimates are shown below. Obviously the long term margins which the sell side is modelling in look very conservative. On the positive, this is a very cash generative company giving investors now a 2%+ FCF yield on the EV. But note that SBC has been growing at faster pace, so net-net we’re probably looking at a few percentage points of dilution each year.
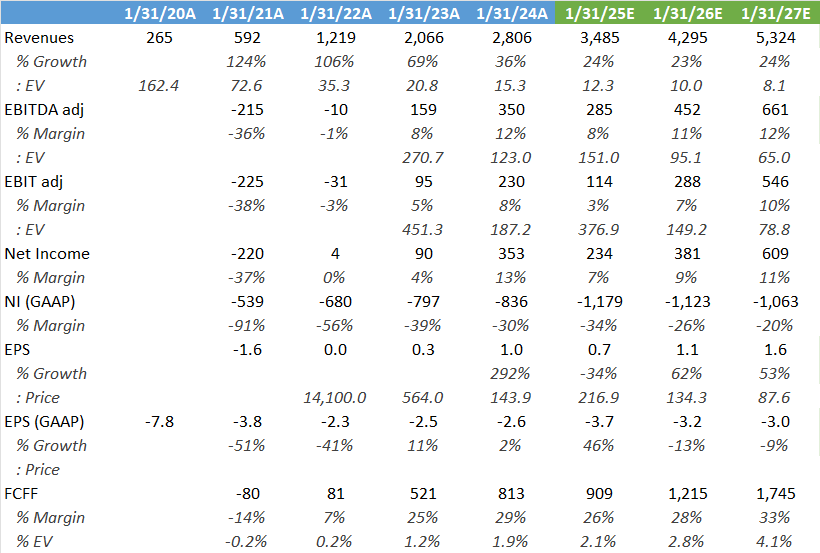
Overall, I continue to like this set of opportunities for Snowflake i.e. the continued migration of data from on-premise environments to the cloud, Snowpark for data science, data sharing for collaboration, and Iceberg tables for open-source storage. The main negative is that the market seems to be moving to an environment where now four players are competing compared to the easier ride Snowflake had beforehand, where it was disrupting first and second generation data warehousing solutions.
So it’s fair to say that my conviction in this name has dropped a bit. As one year ago I was thinking that Snowflake was going to be an easy multi-bagger, trading at $140 and below. Although I do think that this can still be an interesting story for long term shareholders. However, it is obviously one that needs to be monitored..
AMD vs Nvidia at Computex
Both the Nvidia and AMD CEOs gave their respective keynotes at the Taiwan Computex conference over the last few days.
Jensen once again made a solid presentation, explaining how computing has evolved over the last decades and how Nvidia’s innovations finally enabled the LLM revolution we’re currently in. We got a fresh tour of Nvidia’s ecosystem and Jensen ran through how Infiniband is still the preferred networking technology in AI training, as it is designed to handle high bursts of data transfers.
The highlight of the show were the names and roadmaps for Nvidia’s next platforms, which will be called Ultra and Rubin. So next year we’ll get the Blackwell Ultra platform and in 2026, Rubin will be released with follow-on Rubin Ultra in 2027. Rubin will be even more comprehensive than Blackwell, including also a Vera CPU:
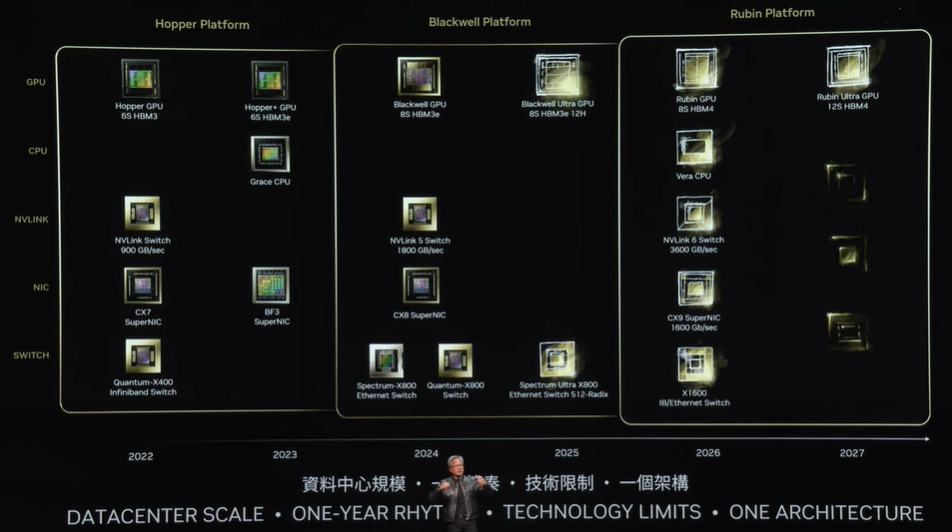
Jensen showcasing what a liquid cooled version of Blackwell looks like:

Jensen also toured what Nvidia is working on in robotics, which is one area he remains bullish on. In this field, the company offers a vertically integrated solution as well, providing the AI training semis for the datacenter, the Omniverse software to train the robots in, for example with reinforcement learning, and finally the Orin and Thor embedded chips to power inferencing on the real-world robots. As all real infrastructure is designed to be navigated by humans, humanoid robots are the obvious solution to automate and handle many tasks. This is a view we share and we’ve also discussed a company in the past which should be extremely well positioned to go after this potentially vast coming market.
So for those who have been following Nvidia, there wasn’t that much new in this presentation. However, as usual, Jensen is a master presenter and it was definitely entertaining and worth watching.
We got some more details from key competitor AMD, who unveiled their strategy to take a larger share of the AI semiconductor market, where they are really a tiny player currently compared to Nvidia.
Firstly, Lisa Su went over AMD’s investments in software to make it easy to deploy AI models on their GPUs. This is one of the key areas where the company has been lagging due to Nvidia’s decades long investments in CUDA:
“MI300X provides out-of-the-box support for all of the most common models, including GPT, Llama, Mistral and many more. We've made so much progress in the last year on our ROCm software stack, working very closely with the open source community at every layer of the stack while adding new features and functionality that make it incredibly easy for customers to deploy AMD Instinct in their software environment. Over the last 6 months, we've added support for more AMD AI hardware and operating systems. We've integrated open source libraries like vLLM and frameworks like JAKs. We've enabled support for state-of-the-art attention algorithms. We've improved computation and communication libraries.
Now with all of these latest ROCm updates, MI300X delivered significantly better inferencing performance compared to the competition on some of the industry's most demanding and popular models. That is, we are 1.3x more performant on Meta's latest Llama 3 70B model compared to H100. And we offer 1.2x more performance on Mistral's 7B model.
We've also expanded our work with the open source AI community. More than 700,000 Hugging Face models now run out of the box using ROCm on MI300X. Our close collaboration with OpenAI is ensuring full support of MI300X with Triton, providing a vendor-agnostic option to rapidly develop performing LLM kernels. And we've also continued to make excellent progress adding support for AMD AI hardware into the leading frameworks like PyTorch, TensorFlow and JAKs.”
Then Su went into their hardware strategy, where the company is moving to one year cadence in the release of a new flagship data center GPU. However, she did play a trick as each time she compared performance to a Nvidia GPU which will be released one year earlier. So she wasn’t really comparing like-for-like in terms of release dates, as Nvidia will already have released a new GPU when AMD's versions come out. Also, when looking at these specs, keep in mind that the software running these chips is even more important..
“We launched MI300X last year with leadership inference performance, memory size and compute capabilities, and we have now expanded our road map. So it's on an annual cadence and that means a new product family every year. Later this year, we plan to launch MI325X with faster and more memory, followed by our MI350 series in 2025 that will use our new CDNA 4 architecture. Both the MI325 and 350 series will leverage the same industry standard universal baseboard OCP server design used by MI300. And what that means is that our customers can very quickly adopt this new technology. And then in 2026, we'll deliver another brand-new architecture with CDNA next in the MI400 series.
So let me show you a little bit, starting with MI325. MI325 extends our leadership in generative AI with up to 288 gigabytes of ultrafast HBM3 memory with 6 terabytes per second of memory bandwidth. Now let me show you some competitive data. Compared to the competition [H200], MI325 offers twice the memory, 1.3x faster memory bandwidth and 1.3x more peak compute performance. And based on this larger memory capacity, a single server with 8 MI325 accelerators can run advanced models up to 1 trillion parameters. That's double the size supported by an H200 server.
And then moving into 2025, we'll introduce our CDNA 4 architecture, which will deliver the biggest generational leap in AI performance in our history. The MI350 series will be built with advanced 3-nanometer process technology and support for FP4 and FP6 data types.
So if you just take a look at that history, when we launched CDNA 3, we were at 8x more AI performance compared to our prior generation. And with CDNA 4, we're on track to deliver a 35x increase compared to CDNA 3. And when you compare MI350 series to B200, Instinct supports up to 1.5x more memory and delivers 1.2x more performance overall. We are very excited about our multi-year Instinct and ROCm road maps.”

I suspect that Nvidia will remain untouchable in AI training in the coming years, and as they remain ahead on both the hardware and software sides, also in inferencing their market share should remain well defendable.
So of these two, I still prefer to hold Nvidia on 39x forward PE compared to AMD’s 41x:
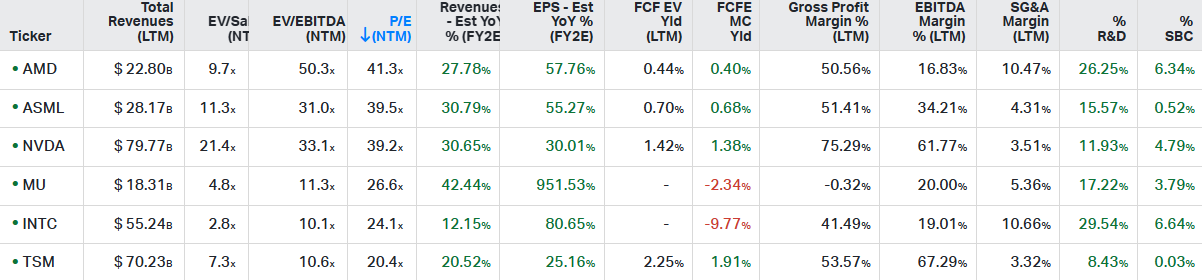
Consensus estimates for AMD below, this is obviously a pricy name and while I like their FPGA business, their position in datacenter CPUs will be seeing increased competition going forward. So if they can take a chunk in the AI datacenter GPU market, obviously we’ll get large upside, but I didn’t see anything here from AMD that would disrupt Nvidia in the coming years..
If you enjoy research like this, hit the like and restack buttons, and subscribe if you haven’t done so yet. Also, please share a link to this post on social media or with others who might be interested, it will help the newsletter to grow which is a good incentive to publish more.
I’m also regularly discussing tech stocks on my Twitter.
Disclaimer - This article is not a recommendation to buy or sell the mentioned securities, it is purely for informational purposes. While I’ve aimed to use accurate and reliable information in writing this, it can not be guaranteed that all information used is of this nature. Before making any investment, it is recommended to do your own due diligence.
Agree that Nvidia is a better investment than AMD. However, I do think AMD will gain share on server CPU from Intel. Granite Rapids and Sierra Forest are inferior as they are done at Intel 3
Thanks! When you did your research, did you come across Exasol? Its a german tiny cap that claims to be similar.