

AI Outlook & The Edge AI S-Curve
We enjoyed Google DeepMind researcher Yao Shunyu’s interview on the Zhang Xiaojun podcast. Previously, Yao was at Anthropic where he helped train Claude 3.7, now he’s involved in the Gemini 3 series. We’ll give the highlights below:
“The pace of model improvement is not slowing down at all. It is hard to quantify the velocity curve because if you only look at standard benchmarks, progress will naturally appear to slow down as scores approach one hundred percent. However, the qualitative difference felt by the user does not scale linearly with benchmark gains. Going from seventy percent to seventy-five percent on a complex task can feel like a much larger leap in usability than going from fifty to sixty percent. As a researcher, my personal observation is that the models’ fundamental capacity to learn is getting stronger. Tasks that used to require massive engineering effort to teach a model can now be achieved with far less friction. The bottleneck is no longer the model’s capacity to learn, but our ability to clearly define the problem and construct high-quality data environments.
My experience is that pre-training scaling has not hit a wall, and I do not see any signs of it plateauing. When people claim the Scaling Law is reaching its limit, it is usually due to one of three things. Either they believe the physical limits of the paradigm have been reached, or they believe we have run out of usable data to scale further, or they simply have an unnoticed bug in their own implementation. In the vast majority of cases where teams hit a wall, it is due to the third reason. In this industry, fixing a single subtle bug in your scaling science or data pipeline can yield progress that far outpaces any fancy algorithmic trick. When you run into a bug, if you believe the paradigm is limited, you declare that you have hit a wall. If you believe it can be fixed, you keep digging. This is why systematic problem-solving, which both Gemini and Anthropic do exceptionally well, is so critical. You must design clean ablation experiments to isolate and test every variable.
Coding has two massive advantages that make it perfect for AI. First, it has a highly objective and well-defined reward signal. If you ask a model to write code to implement a specific feature, you can easily run tests to see if the input matches the expected output. The feedback loop is immediate and unambiguous. Second, coding has an incredible, decades-long data foundation in GitHub, which provides a massive repository of high-quality code written by excellent programmers. This allows researchers to build highly robust simulation environments. From a product perspective, the user requirements for coding are relatively singular and standardized. Unlike social media or gaming, where user tastes are highly subjective and diverse, excellent programmers generally agree on what constitutes clean, concise, structurally clear, and well-abstracted code. This consensus makes developing coding products much more straightforward. AI can write specific code blocks incredibly well, but breaking down a massive, ambiguous project into actionable, modular steps is still a human-dominated skill—at least for now.
A conservative estimate is that over ninety percent of the raw code I use is model-generated. If I am being less conservative, it is closer to ninety-nine or one hundred percent. However, I still spend a significant amount of time reviewing, editing, and verifying the logic to ensure it aligns with my exact design. The core of software engineering has shifted from writing syntax to designing system architecture, defining logic, and providing the model with the right context and reference files. The portion of code that the model cannot write is shrinking rapidly. Compared to eighteen months ago, the efficiency of implementing ideas and running research experiments has increased by twenty to fifty times. You can run multiple experimental ideas in parallel, and let the model monitor the runs and analyze the results. This has actually made my working hours longer and more intense; because the iteration cycle is so fast, there are constantly more ideas I want to test immediately. In the generative AI field, no one is coasting. If you are self-driven and passionate about the technology, the pace is incredibly demanding.
The absolute capability gap between Chinese and Western AI models is narrowing, and Chinese model developers have gotten incredibly good at building competitive models despite facing severe hardware and compute constraints. However, whether they can completely close the gap or surpass Western models remains an open question. The compute disadvantage has forced Chinese labs to become highly innovative in other areas, such as model distillation and multi-agent training systems. Model distillation is an open secret in the industry, but there is a major difference between brute-force distillation and smart, soft distillation.
Brute-force, or hard distillation, involves simply taking a massive batch of outputs generated by a model like Claude and training your own model directly on those tokens. Commercially, this is questionable, and intellectually, it is somewhat foolish because it shows that a team does not know what they want to build; they are merely copying someone else’s distribution to score higher on standard benchmarks. On the other hand, soft distillation involves using other models as assistants or evaluators within your own proprietary data generation pipeline. This is a fascinating scientific approach. It has effectively turned some Chinese labs into pioneers of multi-agent training systems, as they are integrating diverse model distributions into a single cohesive training ecosystem. ByteDance’s Doubao is quite distinctive; while it may not match the raw reasoning intelligence of Gemini or Claude, its real-time voice generation is arguably the best in the world. They have optimized heavily for their specific consumer user base, prioritizing low latency and engaging user experience over raw benchmark performance.
Before Claude 3.7, post-training was largely a process of patching up pre-trained models rather than a scalable paradigm of its own. The breakthrough came when the industry figured out how to scale reinforcement learning by utilizing clean, objective environments with clear feedback signals—specifically software engineering environments. The core development of Claude 3.7 took about four to five months. My work was focused on the algorithmic stability of large-scale RL and building the modular training environments. However, AI development at this scale is a massive, highly collaborative systems engineering effort. The era of individual heroism in AI is over; the technology is an unstoppable wave, and researchers are simply surfers trying to catch the crest. If one individual does not make a specific discovery, another team in a well-funded lab inevitably will a few weeks later.
Anthropic has a highly effective, top-down decision-making structure. Because the core technical leaders like Jared Kaplan and Sam McCandlish are also co-founders of the company, they possess immense technical credibility and corporate authority. When they receive a clear technical signal, they can instantly align the entire company to go all-in on a specific bet, such as prioritizing coding capabilities. This is very difficult for other companies to replicate. At OpenAI, internal political struggles disrupted this alignment, and at Google, the organization is historically much more bottom-up and distributed. Anthropic’s co-founding team has a deep level of mutual trust built from fighting battles together since their days at OpenAI, which keeps the organization incredibly reactive and focused.
I left Anthropic due to several factors. First, Anthropic grew very rapidly, more than doubling its headcount to nearly two thousand people while I was there. This rapid growth introduced significant cultural dilution and internal friction. I personally dislike cultures where people spend their days on Slack talking about grand, abstract principles rather than doing the hard, meticulous engineering work required to implement ideas. Second, I disagreed with the increasingly extreme and emotional anti-China political stance pushed by Anthropic’s leadership. Finally, Anthropic is highly focused on a narrow product set, meaning they do not invest in low-level infrastructure research or multimodal generation. I wanted to learn from a broader set of human minds and have the freedom to explore diverse research directions, and Google DeepMind offers an unparalleled environment for that scale of research freedom.
If your goal is to immediately force your specific idea into a consumer product, Google’s massive size and complex release processes can be highly frustrating. But if your goal is research freedom and accessing world-class engineering talent across a massive spectrum of technologies, there is no better place. Google’s technical reserves are unmatched. Additionally, OpenAI’s early success actually saved Google by waking the giant up. It forced Google to reorganize and streamline its decision-making, transforming pre-training into a highly disciplined, predictable engineering process that operates completely within Google’s comfort zone.”
This bodes well for the future of AI investment—scaling laws are alive and well, models are becoming intrinsically more intelligent, and so AI will continue to be able to solve a wider diversity of problems, and more complex ones. However, going forward, capex growth rates will moderate from the hyperfast expansion we’ve seen over the past few years:

Besides the law of large numbers, another key reason for moderating growth rates is that the four largest hyperscalers are now hitting their limits in terms of what they can afford without having to raise large amounts of debt or equity:
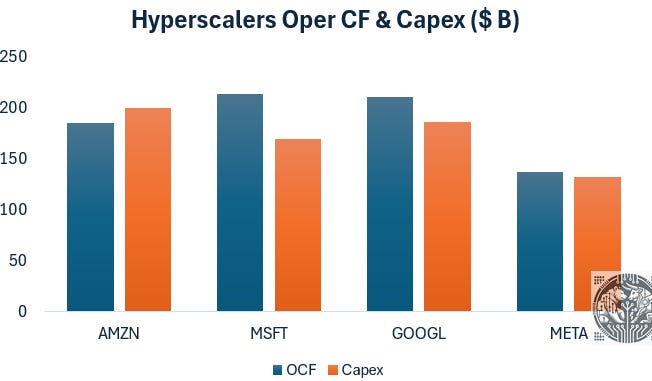
It’s likely that in the coming years, hyperscalers will continue to expand capex as operating cash-flow continues to grow, as raising large amounts of debt and equity to go free cash flow negative will likely impact their share prices, as we’re seeing with Meta for example.
Meanwhile, also neoclouds are getting stretched in terms of what they can spend on data centers:
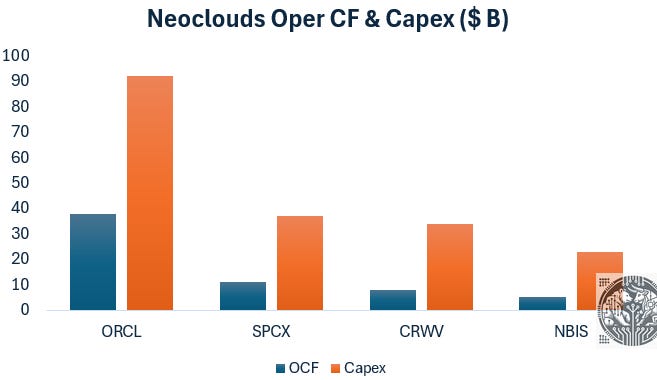
Due to the huge surge in AI capex over the past three years, the strongest outperformers in the market have been the AI capex beneficiaries. However, in our view, the party isn’t over yet for semi investors as once the growth in AI data center capex slows down, it’s likely that a new S-curve will start to emerge in edge AI. One obvious application of edge AI is inserting intelligence into a smartphone.
Apple, which was still TSMC’s largest customer last year, knows that it has to get its AI strategy right. Missing the boat on edge AI—for example, with Google or Samsung launching a much better AI smartphone—could pose a big risk. In order to run a smart AI model on the edge, loads of DRAM are needed. This means that Apple will have to use its cash reserves to book new capacity at the three DRAM players. From the Wall Street Journal:
“Compounding the issue is Apple’s need for additional DRAM to support more AI features, including a rebooted Siri announced last week. And the company has long used NAND storage upgrades to boost profits, charging $100 to $200 for extra increments that cost it just a fraction of that. In the interview, Cook said Apple stands ready to use its cash reserves to boost memory supply. “We’re willing to use our balance sheet to help be a part of the solution,” he said. “Obviously, more capacity is needed.”
Mobile is still massive for the DRAM manufacturers—at 32% of revenues, Mobile & Client make the same contribution to Micron revenues as the cloud:
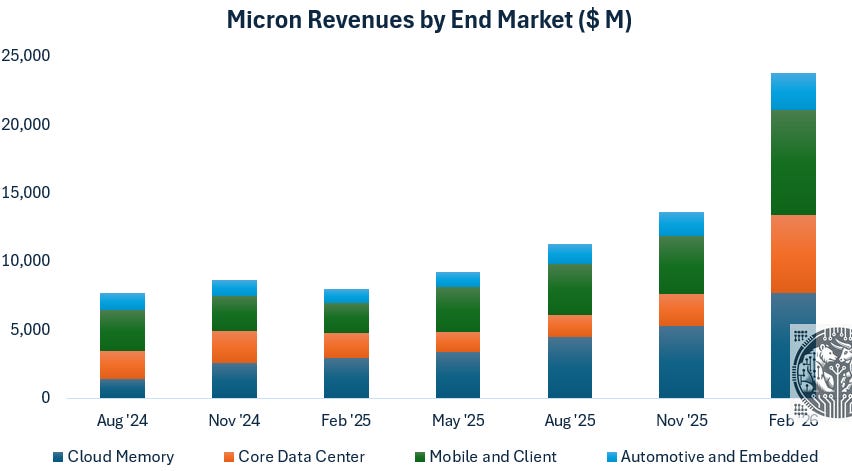
For investors wondering where to position in memory, our view continues to be that DRAM is much more attractive than NAND. DRAM is really the fast memory that enables AI, whereas NAND is basically storage where you store the chat history, or offload the KV cache as it grows too large.
In addition, DRAM is a highly consolidated three player market with more differentiation in HBM, whereas NAND is a more commoditized product with five significant manufacturers, increasing the risk for overcapacity at some stage. So, we expect DRAM to continue to enjoy the largest price increases:

Besides mobile, also physical AI (robots) is likely to become a large semis market in the 2030s. If, ten years from now, 100 million humanoid robots are sold per annum (vs a smartphone market which is currently at 1.25 billion units annually), this would translate into another semi TAM of $600 billion. For comparison, Nvidia will be doing $390 billion in revenues this year.

Yao Shunyu explains the current challenges still to develop humanoid robots:
“I have looked at some of the humanoid robots and their pricing; the hardware supply chain in China is incredibly mature, making these physical platforms surprisingly cheap. However, on the software side, robotics is still very much in its feature engineering era. Robots can be optimized to perform incredibly well in highly specific, deterministic environments, but they lack generalizability. If you train a robot to fold clothes or pour water, that capability does not naturally abstract and generalize to other tasks. Language models have crossed that critical threshold where scaling up the base model lifts all downstream capabilities simultaneously. Robotics has not yet reached its GPT-1 moment; we have not figured out how to truly scale the training of physical action models. Many robotics labs are now experimenting with using multimodal language models as a base, training vision-language-action models to bridge this gap. Visiting these labs is incredibly fun—they are far more dynamic than language model offices, with researchers constantly collecting physical data and controlling machines.”
XPeng’s founder goes deeper on the various challenges in robotics, although he estimates the company can start mass production of its humanoid robot ‘Iron’ next year already—these are the highlights from his interview on the Zhang Xiaojun podcast:
“What works for digital AI cannot simply be copied to physical AI. It is a completely different world. When digital AI companies try to define the physical world without ever having run a physical business, they build physical AI in a very narrow sense. The actual physical world involves complex human interactions, environmental variables, regulatory compliance, and commercial viability. You have to think far broader than just having a couple of strong features. That is why digital AI CEOs cannot easily explain the transition to physical AI; they are still discovering if they can even succeed.
XPeng’s robotics journey actually spans three distinct stages. The first stage was from 2018 to 2020. It was an independent team of about four or five companies in China exploring quadruped robotics. The second stage was from 2020 to 2023. Over those four years, we built three different milestones. We tried making robots using traditional robotics methods and even tried making robots the way we make cars, stitching various elements together with mixed success. The third stage began after 2023. When we saw the progress of foundation models in late 2022, our entire logic changed. Previously, we believed it was impossible to build a successful robot brain because the complexity of the cerebellum—maintaining physical balance and motion control—was too high.
Today, many companies claim they have developed a robot cerebellum because their robot can walk forward slowly at a monotonous pace. That is not a cerebellum; that is just a basic spine or brainstem maintaining balance. They are far from achieving true cerebellum functionality. Many of the robot demos you see from other companies today are still utilizing what we consider third- or fourth-generation technology stacks. They are just running basic tests. At XPeng, we have the patience and courage to invest for the long term. A quick demo means very little. It is just like back in 2017 when China had hundreds of autonomous driving startups showing off level 4 data; very few of those technologies ever translated into real, commercialized value.
Cars have a highly mature process spanning from planning and design through start of production. By the end of this year, we hope to transition our robots into an automotive-grade start of production process. By 2027, we expect high-level robots to enter their first true year of commercial mass production globally. At that point, traditional motion-controlled robots will begin to decline as advanced physical AI robots take over.
From the end of last year through the first half of this year, our robotics department alone hired nearly eighty master’s and doctoral graduates from top-tier institutions. They are incredibly expensive, but we are fully committed to supporting their long-term exploration. We believe that we must use super-smart people to solve super-difficult problems, rather than relying on rigid processes and predefined tools.
Starting a robotics business is vastly different from starting a car company. I believe starting a robotics company is twenty to one hundred times more difficult than building a car company. Even with XPeng’s established manufacturing and AI capabilities, our success last year only increased our overall probability of success by a small margin. Today, there are over two hundred robotics startups established in China, which is double the number of electric car startups we saw during the peak of the automotive boom. However, unlike cars, which are primarily categorized into passenger, commercial, or special vehicles, robots will have countless classifications, ranging from medical and freight transport to cargo inspection. Many of these specialized robots do not need to be humanoid. But on the path of universal bipedal humanoid robots, ninety-nine percent of companies will fail. The software complexity is simply too high, and there is no open-source platform capable of helping a robotics startup build high-fidelity physical AI software. We are focused on navigating these pitfalls ourselves because you only truly understand the engineering challenges once you step on the traps.
Traditional automotive motion control has been largely commoditized over the last century, with car companies purchasing motor controllers from Tier 1 suppliers. But to make a robot truly capable, its motion control must be far more integrated and responsive than a car’s. In a car, different control domains are isolated. This works for standard driving, but if a car has its left tires on snow and its right tires on grass, executing a forty-seven-degree turn with a person suddenly appearing in front of the vehicle is incredibly difficult. Managing four-wheel traction, movement balance, and latency under those conditions remains a challenge.
For a robot, the complexity is multiplied. A human has over two hundred joints, allowing for an infinite loop of potential movement combinations. Replicating this full-pose personification using AI-driven motion control rather than rule-based software is incredibly difficult. We want to give our robots the same physical instinct a human has when walking on snow, ice, or grass, sensing friction and adjusting balance instantly. This is why we develop eighty percent of our robot hardware in-house, including our actuator joints and hands, while cooperating with upstream Tier 2 suppliers to scale quality.
Once a robot achieves generalized software capabilities, its market adoption and production scaling will happen far faster than cars. Cars took a century to scale because we had to build global road infrastructure, establish traffic regulations, and manage highly complex manufacturing logistics. Robots can be deployed instantly into existing human environments. If the software is ready, physical AI will scale rapidly.
Over the next few decades, universal humanoid robots will become deeply integrated into human lives. While digital AI is limited to assisting in a few dozen white-collar roles, physical AI robots can address hundreds of physical roles, especially in aging societies. I believe the two most critical factors for the future of humanity are medical AI to help the elderly live longer, healthier lives, and physical AI robots to provide care and companionship. For many elderly individuals, a robot may eventually become their primary support system.
We chose this difficult path because we analyzed the fundamental flaws of other forms. For example, we previously developed quadruped robots—dogs and horses. But if you bring a robot dog that is over a meter tall into a standard home, it cannot function. It cannot turn around next to a bedside table without scratching the walls or damaging the bed. Unlike a real golden retriever whose tail and body are soft, a rigid robot dog will inevitably cause damage. If you make the robot dog smaller, its battery life becomes too short, and its utility drops to basic companionship.
If you build a massive, 1.8-meter bipedal robot covered in heavy metal armor, even its own designer will feel an intense sense of physical oppression standing next to it. You will naturally worry about it falling, overheating, exposing high voltage, or simply being dirty. If adults feel that way, how will children and the elderly react? How do you resolve those safety and legal regulations in a household setting? While industrial robots can utilize that design because they operate in controlled environments, household robots must be designed differently. They must be comfortable for humans to interact with. That is why our current generation of robots is designed to be around 1.69 to 1.70 meters tall—a height that is comfortable for both men and women. They are designed to wear clothes and can even have hair, but they must not have a realistic human face to avoid the uncanny valley effect and other complex sociological issues.”
Next, we will dive into a small company that’s an advanced silicon player in edge AI. We see the long-term risk-reward as very attractive in this name, and it reminds us somewhat of investing in Nvidia in 2015, when AI and data center GPUs were only at their very early beginnings. Eight years later, demand fully exploded. It’s likely that a similar scenario will play out when it comes to edge AI and robotics.