

AI beginnings, Nvidia’s CUDA computing platform
CUDA was probably the key driver allowing Nvidia to build up such a dominant position in AI training. Ian Buck fathered the concept. While studying at Stanford, he had the vision of running general purpose programming languages on GPUs. Nvidia liked this idea and funded his PhD, out of which came a new programming language called Brook. Prior to this, GPUs had to be programmed with specialized graphics programming APIs such as DirectX or OpenGL, a rather cumbersome process. Which also dramatically lowered the available talent pool to unlock the tremendous computing power of GPUs, as most developers would be skilled in general purpose programming but much less so in graphics programming.
After this initial GPU engineering at Stanford, Buck went a few miles south-east to turn this into a commercial product at Nvidia. Two years later, in November of 2006, the first CUDA platform shipped with the Geforce 8800. The choice had been made to move away from Brook and allow instead for Nvidia’s GPUs to process C/C++ code. The main reason was that a lot of developers didn’t really want to learn a new language and C/C++ happened to be the key programming language in the gaming industry, as well as for other high-performance applications. This would allow enterprises to tap the wide and diverse talent pool of gaming programmers to use this new toy for huge computational workloads.
An Anandtech article written at the time explains this new CUDA feature: “The major thing to take away from this is that Nvidia will have a C compiler that is able to generate code targeted at their architecture. We aren't talking about some OpenGL code manipulated to use graphics hardware for math. This will be C code written like a developer would write C. A programmer will be able to treat Geforce like a hugely parallel data processing engine. Applications that require massively parallel compute power will see a huge speed up when running on Geforce as compared to the CPU. This includes financial analysis, matrix manipulation, physics processing, and all manner of scientific computations.”
The matrix manipulation is the huge one, as this would become the workhorse of machine learning in the subsequent decade.
Nvidia’s docs explain the differences between a CPU and GPU: “While the CPU is designed to excel at executing a sequence of operations, called a thread, as fast as possible and can execute a few tens of these threads in parallel, the GPU is designed to excel at executing thousands of them in parallel. The GPU is specialized for highly parallel computations and therefore designed such that more transistors are devoted to data processing rather than data caching and flow control. The schematic shows an example distribution of chip resources for a CPU versus a GPU.”
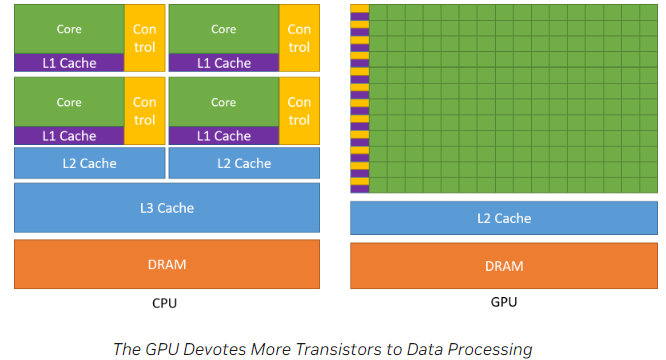
Initially CUDA found its usage in high-performance computing, simulation, and other scientific endeavors. However, the really big opportunity started to emerge in 2012, when researchers up in Canada managed to train a 60 million parameter neural net on a GPU which could classify millions of high-resolution images. This was immediately useful as it enabled the large internet companies to understand the content their users were posting. This really catapulted the field of machine learning with one breakthrough after another up to this day.
An illustration below of a neural network where each neuron in a layer is connected to each neuron in the subsequent layer via a weighting, which determines the width of the connection. The optimal weights are found by calculus, i.e. derivation, and large amounts of iteration. All sorts of computations for which GPUs happen to be ideal.

A recent key innovation in this field are the transformers, developed in 2018 at Google and popularized by OpenAI towards the end of 2022 with ChatGPT. Ian Buck explains this innovation at the recent Rosenblatt conference:
“Prior to that, most applications, they were convolution-based. They were basically looking at neighborhoods of information and building up an understanding from localized data. This makes sense in image recognition to recognize the face. Transformers were based around the idea of attention, figuring out distant relationships and incorporating them into a neural network. There's no database back there. It's one large neural network But the reason why ChatGPT is so big, the 530 billion parameter model that we trained on our supercomputer, it has to capture humanology at some level. I think we're at that cusp of really the beginning of generative AI. There are one trillion parameter models behind closed doors. They're starting to get a little more secretive and not releasing these huge models.”
AI-coding-king Pytorch is welcoming AMD
Pytorch has become the dominant framework to write AI models. This library basically provides Python objects and functions so that you can write all your needed AI code in user-friendly Python. Underneath, Python is running on less user-friendly C, which is extremely fast and in communication with the GPU's computing platform, CUDA.
Historically, competing framework TensorFlow used to be dominant but now both the academic and professional world have largely shifted over to Pytorch. The reason is that Pytorch is much more granular, you can write your AI code exactly the way you want it to run. Compared to TensorFlow’s Keras deep learning framework which provides a very user-friendly solution out of the box but is much less customizable.
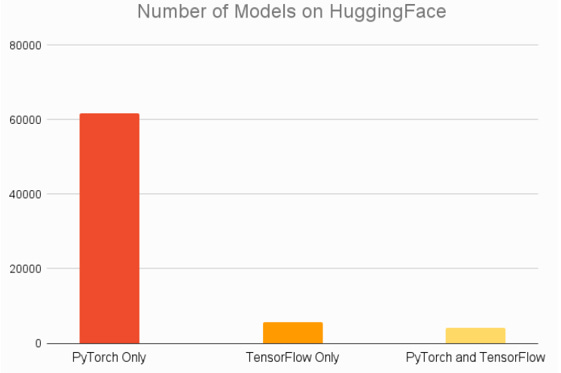
Hugging Face is an online platform for developers to share AI models and illustrates Pytorch’s dominance:
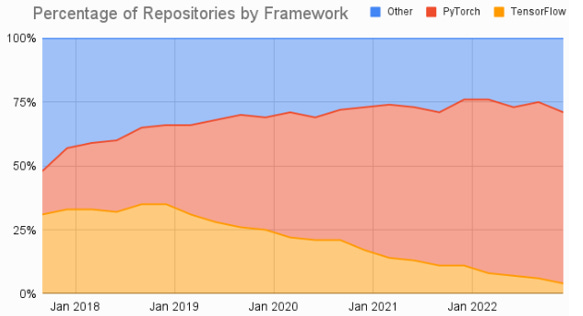
Similarly academics have largely shifted towards Pytorch (chart from AssemblyAI):
Now, as CUDA was historically the only computing platform allowing a general purpose programming language to run on a GPU, and as Nvidia’s GPUs were widely available due to their dominant position in the gaming market, each of these Python AI libraries are underneath running on top of CUDA. They also provide support for CPUs but all serious AI training is happening on GPUs anyways. You might train a home hobby project on a CPU for example.
So this meant that you couldn’t purchase an AMD GPU and run your Pytorch or TensorFlow code on it. Whereas all Nvidia GPUs had built-in support for CUDA and hence allowed them to be easily adopted for AI training. That’s a big problem for AMD.
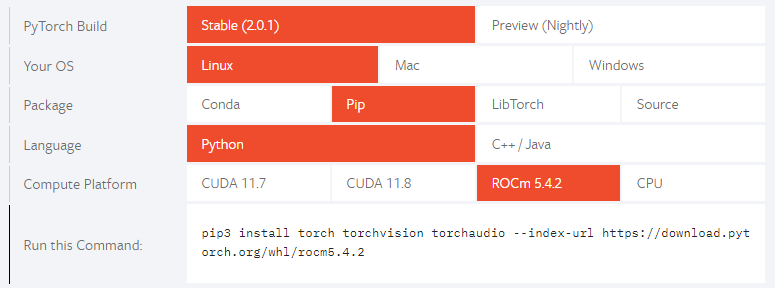
Things are gradually changing. AMD has been building out their GPU computing platform as well, named ROCm (‘rock-em’). And the screenshot below is highlighting how their platform is now supported out of the box by Pytorch for Linux operating systems. Support on Windows and Mac systems is still work in progress. But as Linux is the main operating system in the server market, and that’s where all the serious AI training is happening, it’s really the key end-market anyways.
Last month, Pytorch's founder presented at AMD's datacenter event highlighting the investments both sides are making to increase collaboration. At the same event, Hugging Face’s CEO commented that ‘it’s really important that hardware doesn’t become the bottleneck or gatekeeper for AI when it develops’. AMD for their part has been consolidating all of its AI activities under Victor Peng, which should put them in a better position to further build out their software ecosystem with these crucial partners.
Similarly TensorFlow is building out support for ROCm as well. This library was originally developed at Google but they are now moving in a second direction with the development of Jax, a more functional oriented AI library. Looking at the Jax website, there is only support for CUDA on GPUs available currently, although the framework can also be ran on Google’s TPU accelerators in the cloud. The TPU is a customly designed AI chip by Google for both training and inferencing, i.e. making use of a pre-trained model. From Jax’s website:

The overall conclusion here is that gradually the AI ecosystem is building out support for ROCm as well which would allow AMD’s GPUs to be easily utilized for AI training. Developers could rent then servers in the cloud for AI training and be unaware of which GPUs are doing the actual training underneath. Similar to how you might be unaware of whether your PC is running on an Intel CPU or one from AMD. This hardware fragmentation has already been playing out in the cloud CPU world as well..
The datacenter CPU world is fragmenting
While it’s widely known how Intel has been bleeding share to AMD over the last five years in the datacenter market, newcomers are looking to get a piece of the action as well such as Ampere, which has been designing high-core-count CPUs optimized for cloud workloads.

Amazon’s AWS is in an even better position to take further share, as they can leverage from their extremely strong position in the cloud (chart from Statista):
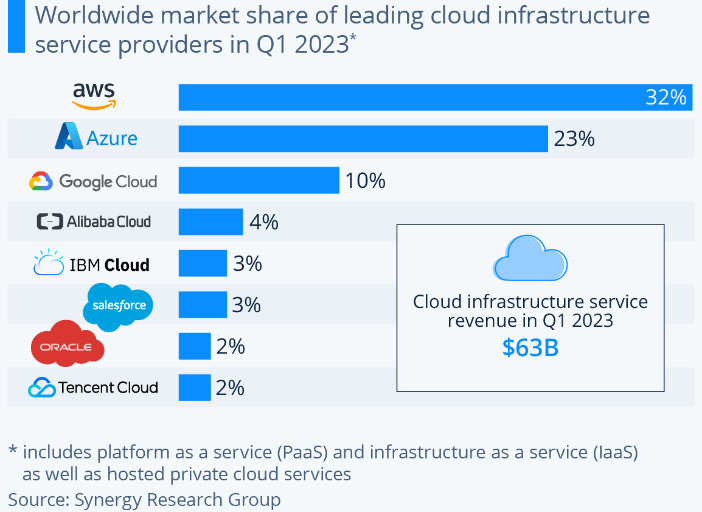
RedPanda explains AWS’ new Graviton chip: “If the initial Graviton was Amazon dipping its toes into the CPU pool, Graviton 2 was a cannonball from the highest diving board. Available around mid-2020, Graviton 2 was a significant leap over its predecessor. It had better than 50% per-core performance and, more importantly, much larger and more varied instance types, with up to 64 cores and up to 512 GiB of RAM. Many testimonials followed Graviton 2’s release, showing that these Arm-powered instance types offered a significant boost for price/performance over x86 instances.”
Reading through a variety of blogs, Graviton’s performance looks very competitive to Intel’s. One of Graviton’s key attractions is that the chips are based on an ARM architecture, which allows for code from major languages such as Java and Python to be easily ran over these CPUs. For compiled languages, such as C++, you will have to recompile your code but this is fairly easily done and just takes a bit of time.
This illustrates the Intel bear case well. Not only will Intel have to execute on a very ambitious technology roadmap in their foundry business, at the same they are likely to continue to bleed share, especially in the datacenter CPU market. Can they make up for it by taking share in the GPU market?
An overview of the challengers in Nvidia’s AI training market
The risk for Nvidia is obviously that the cloud GPU market will go down a similar path as the cloud CPU market, i.e. with the build-out of a better AI software ecosystem allowing for more hardware players to come in. We won’t see a plethora of players coming in, as state-of-the-art GPU design is extremely complex, with estimated costs ranging from the hundreds millions of dollars to over one billion to design an advanced GPU. But there is the risk that a handful of players with deep pockets could come in to get their share of the pie. Besides AMD, I’m thinking of names such as Amazon AWS, Microsoft, Google and Intel.
Intel is working both on a GPU series named ‘Gaudi’, which is starting to get decent-ish results on some tests, more on this later, as well as a software computing platform ‘oneAPI’ meant to compete with CUDA. The latter is probably an overly ambitious attempt. It aims to support all hardware, from different vendors as well as all types, from CPUs, to GPUs, to FPGAs.
Amazon, in a similar fashion to their Graviton CPU, has recently launched their Trainium GPU. They provide a software kit, the AWS Neuron SDK, which allows you to run Pytorch code on Trainium. Given that AWS has a strong position in the cloud hyperscaler market, this should be seen as potentially credible competition.
To expand its GPU market share, AMD has focused its initial efforts on the exascale supercomputing market. HP’s ‘El Capitan’ supercomputer, the world’s fastest, is projected to become operational this year and will be running on AMD MI300A accelerators.
The MI300A will be a combination of CPUs, GPUs and high-bandwidth memory packaged into one unit via a chiplet based methodology. There will also be a purely GPU version available, the MI300X, with the CPU chiplets having been replaced by additional GPUs and high-bandwidth memory. This will benefit certain AI workloads such as large language models.

AMD’s head of datacenter explained their strategy at a recent conference: “In GPUs, we again took a phased approach to attacking the market. And we thought that the most accessible portion of the market was going to be in the exascale, at the very highest end. The software to have the systems optimized was more tractable than in the broader AI market.”
This approach has been successful as AMD did manage to take a share of the supercomputing market:
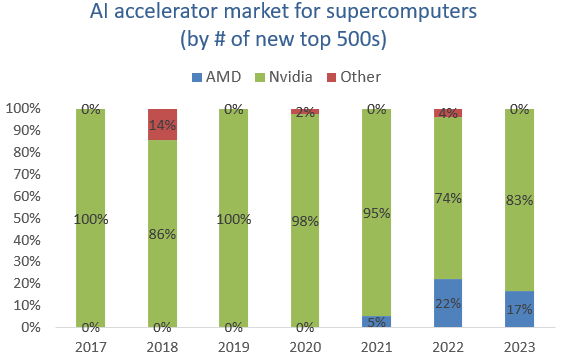
Microsoft is working with AMD on the design for its AI chip. As I understand it, this chip will mainly be used for inferencing, i.e. providing compute to run the already trained ChatGPT models.
So for AMD, the opportunity set is twofold. Firstly, there’s the roadmap to gain share with its own GPUs. While the second pathway is in doing the development work for other large players who don’t have the necessary skills in chip design. Other similar companies who could benefit from this trend include Broadcom, who’s also working with Google on the design of the TPU. And Marvell, another semi designer who has deep capabilities in advanced semi design.
Broadcom’s CEO recently discussed at a conference how they got into supplying Google with their TPU: “This division that does ASICs was approached many years ago by one hyperscaler to develop a very dedicated AI engine focused on the models of that particular hyperscaler. It took a lot of work, some level of investment, but our IP really relates to our ability to manifest in silicon, what is a very complicated AI training and inference chip. And that's how we got into it, being able to having the technology and the skills to create silicon. Not a vision that says AI is the place to be in. We don't do computing typically. It's not an area where we want to come in and compete against players who have been focused on, doing it much longer and will probably out-invest us in that space.”
Tesla is similarly building out their supercomputer for AI training named ‘Dojo’. The entire system is customly designed from the accelerator to the racks, which are all connected to bring in huge sums of processing power. The system is mainly designed with Tesla’s workloads in mind and they reckon this will yield huge improvements versus training on GPUs. For the auto-labeling of sensor imagery for example, they expect to be able to replace 72 Nvidia GPU racks with 4 Dojo ones. And for the subsequent training of the self-driving AI model, they expect Dojo to bring training time down from one month to less than a week.
Musk is aiming to provide this computing platform to the outside world for AI workloads as well, which would make it a competitor to Nvidia and the cloud players. Elon commenting at the latest Tesla capital markets day: “We're continuing to simultaneously make significant purchases of Nvidia GPUs and also putting a lot of effort into Dojo, which we believe has the potential for an order of magnitude improvement in the cost of training. Dojo has the potential to become a sellable service that we would offer to other companies in the same way that Amazon Web Services offers web services. So I really think that the Dojo potential is very significant.”
Recently Musk made some different comments however on the Tesla earnings call: “We're using a lot of Nvidia hardware. We'll actually take Nvidia hardware as fast as Nvidia will deliver it to us. Tremendous respect for Jensen and Nvidia . They've done an incredible job. And frankly, I don't know, if they could deliver us enough GPUs, we might not need Dojo.”
Additionally there are a wide variety of startups looking to get in, semi veteran Jim Keller’s Tenstorrent is one notable example. From their website: “Tenstorrent processors comprise a grid of cores known as Tensix cores. Our processors are capable of executing small and large tensor computations efficiently. Network communication hardware is present in each processor, and they talk with one another directly over networks, instead of through DRAM. Compared to GPUs, our processors are easier to program, scale better, and excel at handling run-time sparsity and conditional computation.”
Tenstorrent provides support for Pytorch themselves, so that you can compile your Python code to run both training and inference on their chips.
Another is UK based Graphcore, although venture capital firm Sequoia wrote the value of its stake down to $0 after the start-up had been valued at $2.8 billion during the covid tech boom of 2020.
Finally, OpenAI’s Triton computing platform is a comparable effort to Intel’s oneAPI aimed at replacing CUDA. Triton is designed to be more user-friendly for GPU programmers, increasing developer productivity. It does this by providing a Python-like programming language, that abstracts away the details of GPU programming, such as thread and block management, memory allocation, and synchronization, which are part of CUDA’s C/C++. Currently Triton is running on Nvidia GPUs but the aim here is to add support for AMD as well.
King Nvidia continues its lead
Naturally Nvidia isn’t sitting still. They remain focused on both providing the best hardware as well as the further build-out of their software ecosystem.
The industry benchmark to measure GPU performance is MLPerf, organized by MLCommons every six months. This test benchmarks a GPU on a wide variety of AI workloads with image recognition, natural language generation and reinforcement learning being a few examples. So it measures both the GPU’s power as well as its versatility in handling a wide variety of tasks. Typically most of Nvidia’s competitors don’t bother to compete, or send in results for only a selected number of AI tasks. Credit to Intel here for competing during the last round, although they did only send in results on four types of workloads.
The results show that Intel’s Habana Gaudi 2 put in a respectable performance against Nvidia’s H100 (Hopper architecture) on ResNet, an image classification task, underperforming only with around 15 to 20%. However, on other tasks it got blown out of the water. So despite talk from many competitors that they have competitive solutions, this is the reason everyone currently is chasing Nvidia GPUs.
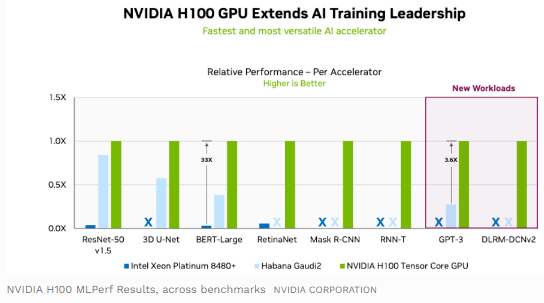
In June of 2022, Google did manage to beat Nvidia on five tests, although they didn’t send in results for the others. Which probably means that their TPU didn’t perform that well on those tasks. However, note here that Google managed to beat Nvidia’s A100 (Ampere architecture), which was already released at the end of 2020. A few months later in 2022, Nvidia released the H100 accelerator.
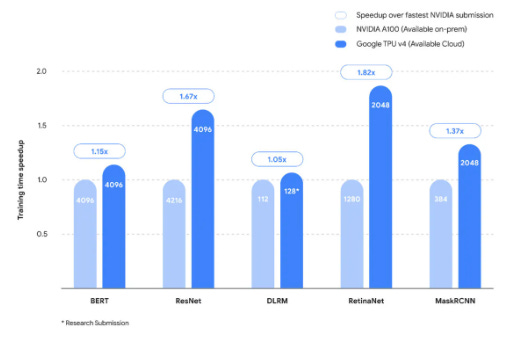
So it’s basically during the last round when the A100 competed that it got beaten:

On a per accelerator basis, Nvidia noted that the A100 actually still won 6 out of 8 tests that year:
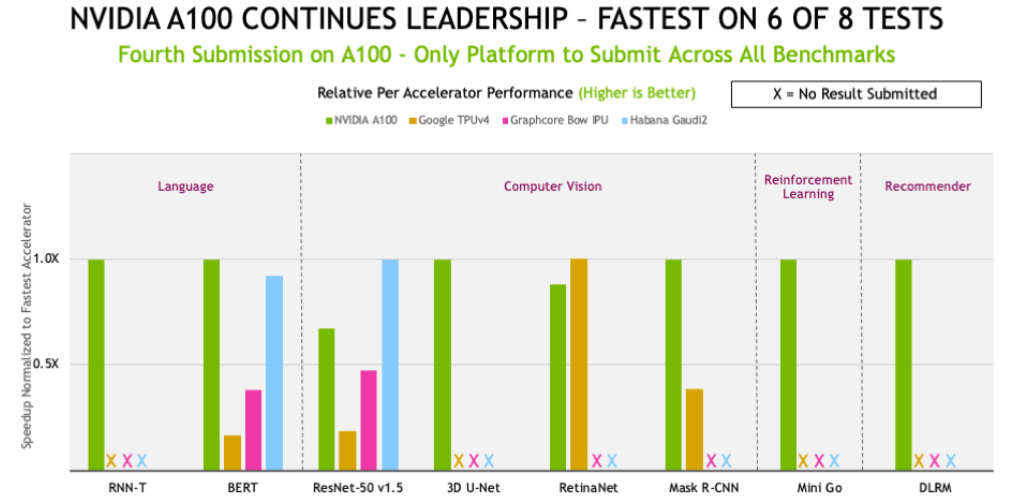
And Nvidia’s latest H100 is again far superior compared to the A100. You can see that Nvidia has been focusing its efforts in expanding the GPU’s capabilities for the handling of transformer based models, which speeds up the training of large language models such as ChatGPT. This is illustrated on the BERT benchmarks below.
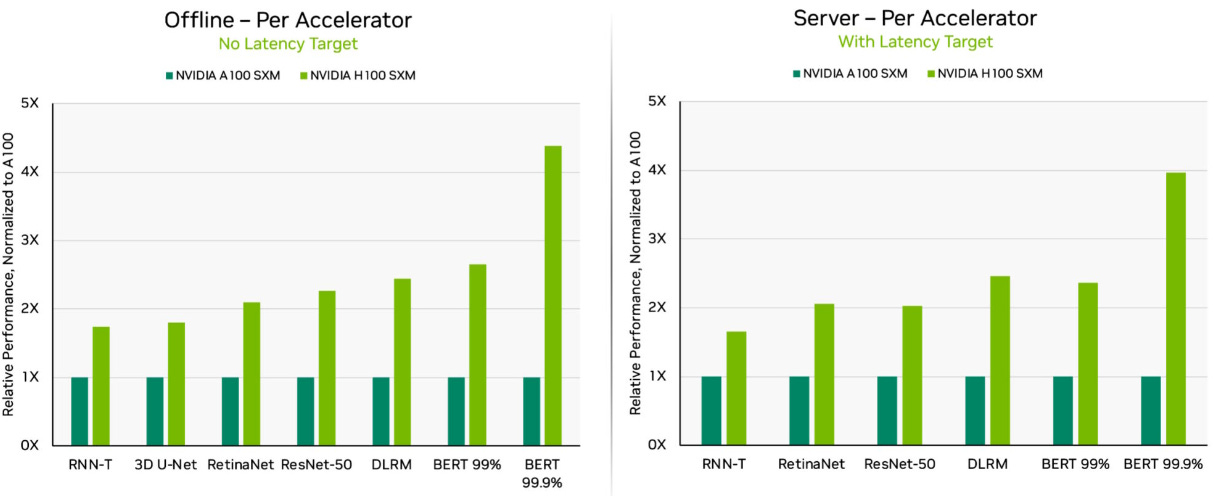
And the H100’s performance will continue to improve. Ian Buck, Nvidia’s current head of high performance computing explains: “The other interesting point is that we don't stop after we ship a new product. We continuously invest in software optimizations. I have hired thousands of software engineers across the company. Nvidia at this point, has more software engineers than hardware engineers. And so after we do the first round of benchmarking on something like Hopper, we continuously improve it. Ampere over its life, saw a 2.5 to 3x improvement from the first time we submitted to MLPerf.”
Designing these high-end chips is incredibly expensive, costing in the hundreds of millions of dollars. And Nvidia, with their deep pockets and wide customer base, has only been speeding up the cadence of this R&D cycle. Thereby erecting an additional barrier for competition to get over. Ian Buck explains: “We've also accelerated the GPU road map. So we used to do a GPU 100-class every 3 years, we're now down to 2 years and in some cases, an 18-month cycle. Jensen has already talked about Hopper Next and that timeline.”
Certain journalists and analysts have been commenting that AMD’s MI300 contains more memory than Nvidia’s H100. However, Nvidia has a nice trick up its sleeve here to double memory capacity. Once again, Ian Buck provides the details: “What Hopper did that was so revolutionary, we made something called FP8, an 8-bit floating point representation. Obviously, computing on 8 bits is faster than computing on 16. Also the memory size is half of what you would have on 16-bits, which is what we had before. And it's a ton of work to make that actually work. To figure out how to keep things within the range of those 8 bits.”
On top of this, Nvidia continues with the build-out of their AI ecosystem..
The wider Nvidia AI product portfolio
As AI workloads moved from being run on one GPU to thousands of interconnected servers, Nvidia decided to acquire Mellanox, an Israeli company focused on high performance interconnect for the datacenter. The company at that time had attractive gross margins of 69%, was growing at a rate of 26%, and was already generating over $1 billion in annual revenues.
Jensen Huang, Nvidia’s CEO, commenting at the time of acquisition: “In the future, we want to optimize datacenter-scale workloads across the entire stack, from the compute node to networking and storage. For this reason, Mellanox's system-to-system datacenter-scale interconnect technology is important to us. We believe our platform will be stronger and deliver the best possible performance for datacenter customers.”
Nvidia recently moved into the CPU market as well, with its Grace CPUs. From Anandtech: “Grace is designed to fill the CPU-sized hole in Nvidia’s AI server offerings. Not all workloads are purely GPU-bound, if only because a CPU is needed to keep the GPUs fed. Nvidia’s current server offerings, in turn, typically rely on AMD’s EPYC processors, which are very fast for general compute purposes, but lack the kind of high-speed IO and deep learning optimizations that Nvidia is looking for.”
The high speed interconnect between Nvidia’s various server processors is established with NVLink, a high-bandwidth and low-latency communication tech developed by Mellanox.
DGX Cloud is an AI training service to rent Nvidia DGX servers over the cloud. You can also access this service through the Microsoft, Google, and Oracle clouds. From Nvidia’s website: “Our DGX GH200 is designed to handle terabyte-class models for massive recommender systems, generative AI, and graph analytics, offering 144 terabytes (TB) of shared memory with linear scalability for giant AI models.”
The company is also adding more software capabilities to their stack. AI Foundations allows customers to finetune pre-trained models with their own data, giving massive reductions in training time as you don't have to train a fresh AI model from scratch. The idea sounds very similar to Hugging Face’s, a community for developers to share AI models. A few examples of how AI foundations can be used:
Nvidia has also been working on a self-driving automotive platform where Mercedes and Jaguar Land Rover are the first prominent customers. The pipeline in this business unit is $14 billion, so this should turn into an annual multi-billion revenue business over time. OEMs can pick and choose from the offering here as they like, e.g. they can purely buy the hardware, or they can also make use of the software for data training. You could purely train a self-driving model in Nvidia’s simulation and then fine-tune it further in your vehicles on a MobilEye system for example.

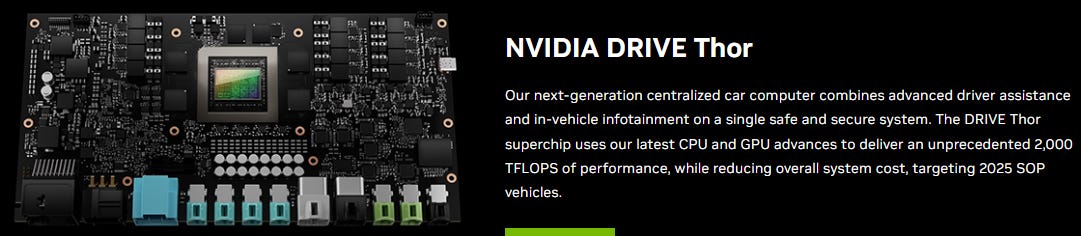
The self-driving system in a vehicle runs on a Thor superchip:
Just like Nvidia has built a digital twin of cities and roads to train self-driving automotive systems, they are doing the same to manage factories. The below image shows Jensen Huang joining in for a BMW team meeting on the virtual design of their new EV factory, using Nvidia’s Omniverse software:
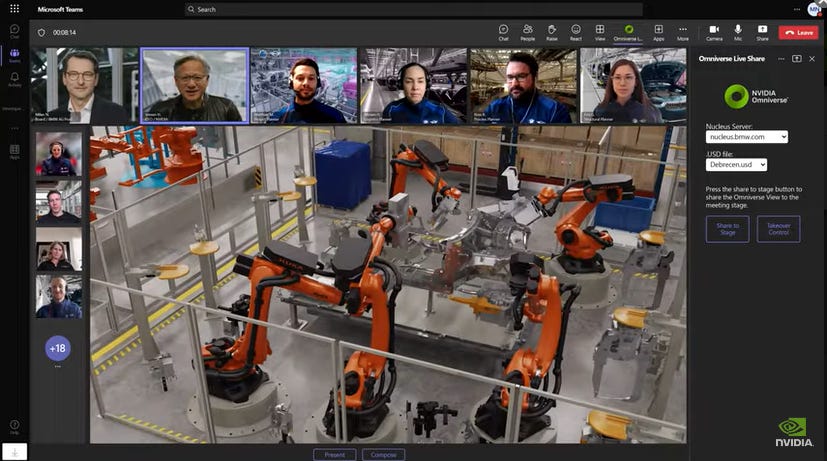
Currently software is only generating annual revenues in the hundreds millions of dollars. But this could become a more interesting growth driver going forward.
What’s next in large language models
Ian Buck also shared some thoughts on what’s next in AI at the recent Rosenblatt conference. Firstly, he went into the limits of neural net model sizes. The key limiting factor here is training time - the larger the model, the longer it takes to train. So developers will build models that will remain practicable to train. This typically means that you should be able to train it in one or two months. If you go past that, your ability to innovate gets hampered as you want the ability to regularly update your model.
Other innovations to improve the neural nets further include more sophisticated mathematics. Ian Buck: “We're continually tuning the intelligence at each layer, making them more optimized, more clever at each layer, which increases the complexity. That isn't always captured in the number of parameters because each layer has a bunch of math and calculations in it instead of just being a naive connections. Human brains behave similar. We have different kinds of neurons for vision processing versus auditory versus memory. The longer you play with something like ChatGPT, you can get it to forget the previous conversation, and it will drift. And that's a function of sequence length, how much of the information of the conversation we can keep in its store. Sequence length increases compute size significantly. We're seeing models integrate more deeply with intelligence databases and applying AI into the database itself. Vector databases are super interesting.”
Inference will be the larger market
How fast the AI market is going to grow is anyone’s guess. Currently projected growth rates range up to 40 to 50%. The below forecast, from Marqual, was forecasting a 17% CAGR but this one was made before the popularization of large language models with ChatGPT. The consensus however is that inference will remain to be the larger market of the two versus AI training. The below chart illustrates this well:
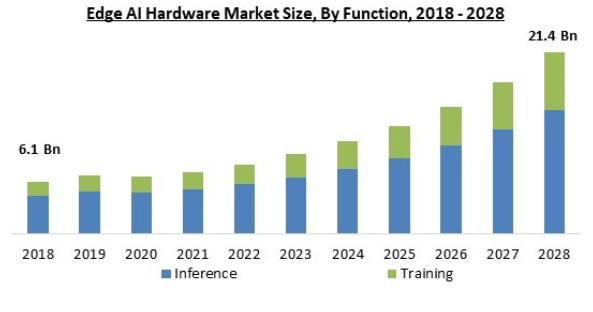
Inference won’t only take place in the cloud but also at the edge of the network, i.e. computing power installed closer to the end consumer, for example on your smartphone or in your car.
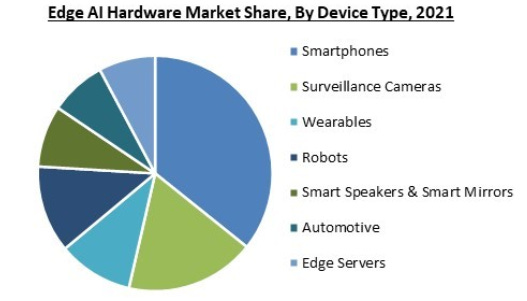
This market is more competitive than AI training, where Nvidia dominates. All kinds of chips are used here, from GPUs, to CPUs, and FPGAs. As a result, a wider array of semi players will be able to compete in this arena with Nvidia, including Intel, AMD, Broadcom, Apple, NXP, and Lattice.
Valuation - share price at time of analysis is $459, ticker NVDA on the NASDAQ
The datacenter market has obviously been the strong growth driver for Nvidia and that line below is going to pop in Q2 as those orders are in the book already:
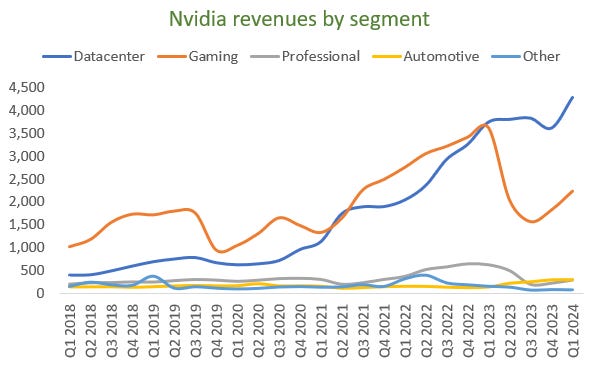
Consensus numbers are already reflecting this:
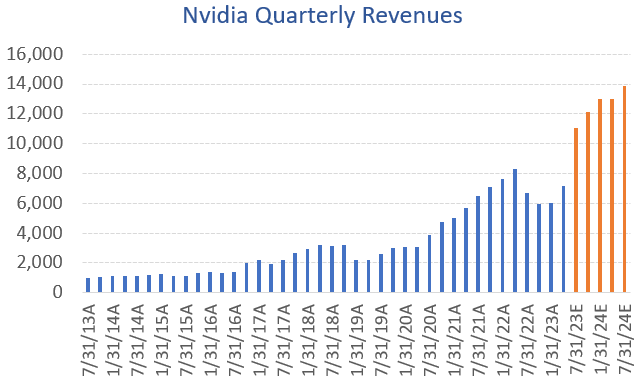
Nvidia is obviously a pricey stock, with shares trading on 33x 2026 consensus EPS, and 44x 2026 GAAP EPS. But do you get an incredibly strong company with top line growth rates expected to be north of 25%. If you think that the correct ‘26 multiple should be more like 40x PE NTM, I get to an IRR of around 15% from now up to January 2025 taking into account some modest share buybacks due to the free cash flow generation.
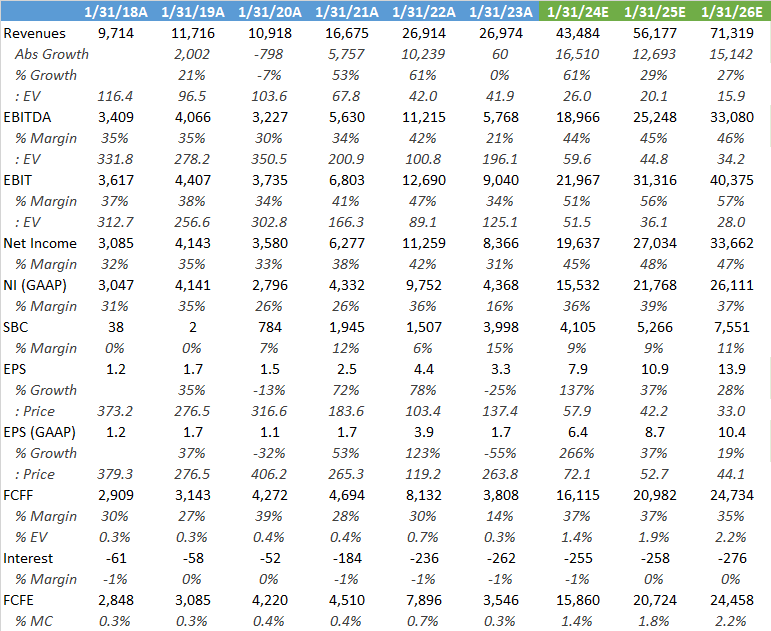
Looking at the AI supply chain, names like ASML and TSMC aren’t good ways to play the thematic as the AI contribution to their revenue base is still too low. TSMC’s last quarterly earnings illustrated this with the CEO commenting: “Today, server AI processor demand, which we define as CPUs, GPUs and AI accelerators that are performing training and inference functions, account for approximately 6% of TSMC's total revenue. We forecast this to grow at close to a 50% CAGR in the next 5 years and increase to low teens percent of our revenue.”
Similarly competitors in training or inference like Intel, Marvell, Broadcom, Amazon, Microsoft, and Lattice have much lower exposures as well.
Obviously the best pure play remains Nvidia with their dominant position in AI training and being largely a GPU oriented company. With their networking business being exposed to high-performance computing as well. AMD is the second best play in my view although they still have a large CPU business, where there is risk of fragmentation in the datacenter as discussed above. However, there could be an interesting delta in their GPU business if they do successfully manage to take some share from Nvidia in AI training.
Nvidia is obviously a very R&D intensive business and this won’t be easy to replicate for competition. There is also significant upside potential on their gross margins, although consensus is already modelling this in.
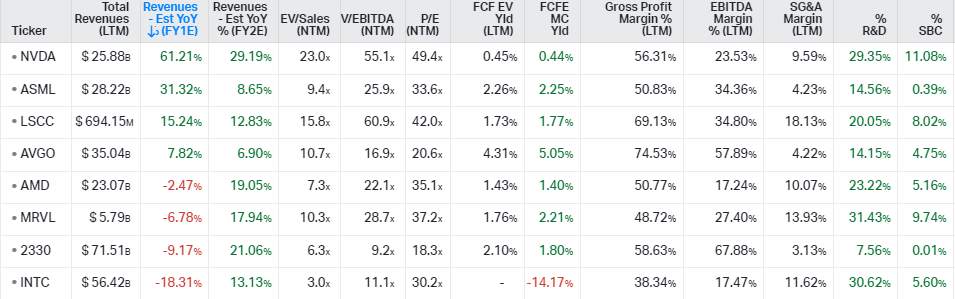
For both Nvidia and AMD, you’re not paying more than in recent history:
If you enjoy research like this, hit the like button and subscribe. Also, share a link to this post on social media or with colleagues with a positive comment, it will help the publication to grow.
I’m also regularly discussing technology investments on my Twitter.
Disclaimer - This article is not advice to buy or sell the mentioned securities, it is purely for informational purposes. While I’ve aimed to use accurate and reliable information in writing this, it cannot be guaranteed that all information used is of such nature. The views expressed in this article may change over time without giving notice. The mentioned securities’ future performances remain uncertain, with both upside as well as downside scenarios possible.
Great write-up! Always knew the moat is in the CUDA software but never really understood it until coming across your piece.
Outstanding write up.