

LLM Commoditization vs Differentiation
One of the big debates in AI is whether LLMs will be a commodity, or whether these will be attractive businesses where a handful of big companies will dominate like we have in big tech today. The commoditization camp will point to charts like the one from Nvidia below, pointing out that open source models are only six months behind and with the gap in capabilities continuing to narrow:
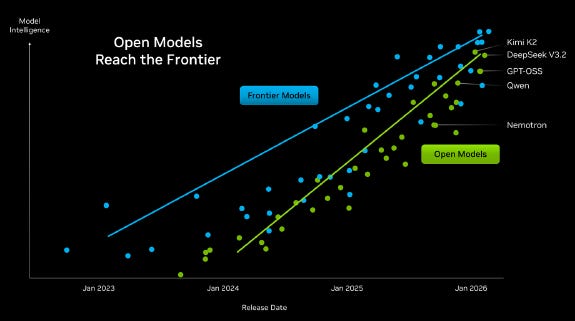
A few key points though to note here. Whenever we’ve tried open source models, the output we get is of lower quality than the leading models. What is likely going on in the chart above is that open source models are heavily trained to perform strongly on benchmarks, whereas with leading models there is also a strong focus to perform in the real world. This is the classic statistical phenomenon of in-sample versus out of sample performance. Just because a statistical or quant model performs very strongly on in-sample data doesn’t mean it will perform strongly once you test it on real data it hasn’t seen before. For example, in quant investing, a backtested and data-mined performance shouldn’t get confused as a reliable indicator for real world results.
Despite the chart showing a narrowing performance, our view is that real world performance between leading models and the rest of the followers will continue to widen. Before, training was heavily dominated by pre-training, which is the phase where you train the model on the available body of human knowledge. However, over the last twelve months, both reinforcement learning and chain-of-thought reasoning have become crucial to get state-of-the-art problem solving capabilities. With reinforcement learning, models can now be trained on unlimited data in particular fields such as mathematics and coding as the model’s proposed solution to synthetic problems can objectively be verified.
This is similar to DeepMind’s training process of AlphaGo nearly a decade ago, where the model that beat the world champion in the boardgame was not trained on human data, but purely on synthetic data by having the model continuously play Go against itself. So, we believe that scaling laws in current AI training are alive and well, and that the increasing capital intensity will make it hard for new players to enter the field. You either need large revenues or access to large amounts of funding in order to compete in this game.
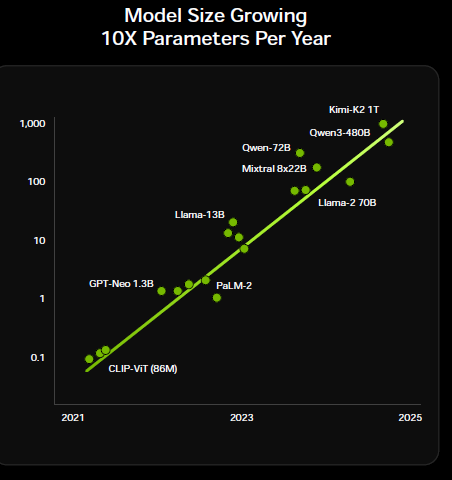
Going forward, another differentiator is that leading firms will have the capabilities to build high-value data sets themselves. This includes hiring investment bankers to teach models how to do financial modeling, lawyers to set up research workflows for legal cases, scientists for scientific research, etc. As the model arrives at its final answer via chain-of-thought reasoning, competition aiming to distil a leading model over API can only memorize this final result. However, these distilled models will struggle to resolve new real world problems themselves.
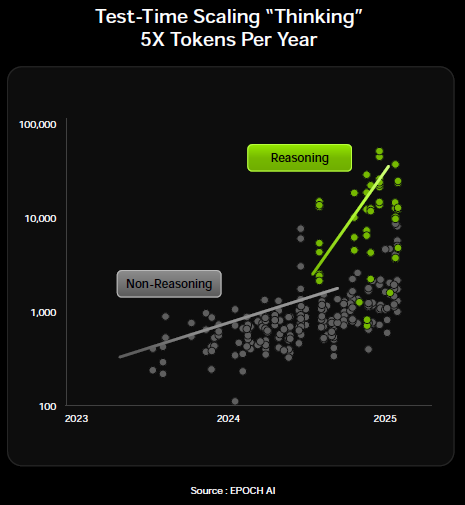
A positive for the big tech firms is that they also have access to unique data sets. Good examples here are Meta with Facebook and Instagram, xAI with X, and Microsoft with LinkedIn. While other providers of high quality data sets such as Reddit will likely continue to steeply increase pricing in return for training access. Amazon is also already blocking access to their shopping site for AI agents, but presumably for a hefty fee this could get unlocked as well.
The key point from the above data points is that capital requirements in order to compete in this race will only continue to grow. Historically, these types of markets have not resulted in highly competitive landscapes with a plethora of competition, but rather a handful of competitors at best. While there is a widespread narrative that LLMs are commodities, we don’t believe this is actually the case today and that it will be even less true in the future. OpenAI and Anthropic scaled to $10-20 billion ARRs within a few years—the fastest ever— providing objective evidence that these businesses have clear differentiated value.
The only counterargument to the above we can see is that big Chinese tech firms can legally purchase high-quality training sets via Chinese data exchanges. For example, while US medical data is fragmented across thousands of private hospitals on different systems, Chinese AI firms have access to large scale anonymized medical records giving an obvious competitive advantage in fields such as medicine and biology.
Another advantage is that China has a ton of engineers which could more cheaply assist models to build workflows. A decade ago, China was famous for data labeling farms, where low-skilled workers tagged traffic photos to train autonomous driving models on. Today, companies like DeepSeek and Baichuan use expert-in-the-loop systems where junior engineers and field specialists write chain-of-thought reasoning paths for models to follow. A big drawback for China is that the country remains heavily short on compute. However, in the long term, it’s likely that China will have the advantage in terms of power generation.
Nvidia vs AMD – Apple vs Android?
At CES, Jensen explained how Rubin will give 5x the performance of Blackwell, despite the number of transistors only increasing by 60%:
“This is the Rubin GPU. It’s 5x Blackwell in floating performance. But the important thing is to go to the bottom line, it’s only 1.6 times the number of transistors of Blackwell. That tells you something about the levels of semiconductor physics today. If we don’t do extreme co-design at the level of every single chip across the entire system, 1.6x puts a ceiling on how far performance can go each year. One of the things we did is called NV FP4 tensor core. The transformer engine inside our chip is not just a 4-bit floating-point number, it is an entire processing unit that understands how to dynamically adjust its precision to deal with different levels of the transformer.
So, you can achieve higher throughput wherever it’s possible by losing precision, and go back to the highest possible precision wherever you need to. You can’t do this in software because obviously it’s just running too fast, and so you have to be able to do it adaptively inside the processor. That’s what an NV FP4 is. When somebody says FP4 or FP8, it almost means nothing to us. Because it’s the tensor core structure in all the algorithms that makes it work. I would not be surprised that the industry would like us to make this format and this structure an industry standard in the future. This is completely revolutionary.”

Next, we will dive into Nvidia’s approach and compare this to AMD’s coming solution. Subsequently, we will dive into more topics in semis and software.