
NeoCloud Economics – Nebius and CoreWeave
Into the weeds

Demand is currently off the charts at Nebius. This is the CEO on the recent call:
“Every time we bring capacity online, we sell all of it. With the new generation of NVIDIA Blackwell coming online, more customers are interested in purchasing capacity in advance and securing it for a longer period of time. Today, we are very pleased to announce that we signed another major deal, this time with Meta for approximately $3 billion over the next 5 years. In fact, the demand for this capacity was overwhelming and the size of the contract was limited to the amount of capacity that we had available, which means that if we had more, we could have sold more. This deal comes on top of the Microsoft deal we announced early in September with a contract value between $17.4 billion and $19.4 billion. As we said before, we expect to sign more of these large long-term deals, and we are delivering that promise.
As busy as we are with these mega deals, our main focus is still to build our own core AI cloud business. We made great progress here with AI native start-ups like Cursor, Black Forest Labs and others. In order to meet the growing demand, we have accelerated our plans to secure more capacity, and this is actually our main focus for now. Capacity today is the main bottleneck to revenue growth. And we are now working to remove this bottleneck. As we look to 2026, we expect our contracted power to grow to 2.5 gigawatt contracted. We plan to have power connected to our data centers, which means fully built of approximately 800 megawatts to 1 gigawatt by the end of 2026, by the end of next year.
We are also investing in our main product, our AI cloud. To extend our addressable market opportunity to large enterprise customers, we released our new enterprise-ready cloud platform version 3.0 called Aether and our new inference platform called Nebius Token Factory. We believe Aether gives organizations the trust, control and simplicity they need to run their most critical AI workloads. Nebius Token Factory is a production scale inference platform that enables organizations to run open source models with reliability, visibility and control. And we have a large pipeline of new software and services that we are continuing to build, which will differentiate us from other cloud companies. Based on the strength in demand that we see and our accelerated capacity growth plan, we believe we can achieve annualized run rate revenue ARR of $7 billion to $9 billion by the end of 2026.
When we plan for data center CapEx, there are actually 3 stages. The first stage is securing the land and power. The second stage is building the data centers themselves including shell, electrical and cooling equipment, batteries and so on. And the third part is finally deploying the GPUs themselves. And it breaks into 3 spending blocks. First stage, securing land and power, it’s pretty cheap. It’s around it’s around 1% of total CapEx. The second stage, building the data centers and building the connected power, is something around 18% to 20%. And the remaining 80% main part, is for deploying the actual GPUs.
So, what should we do? First, we should secure as much capacity as we can because the cost is immaterial at this scale. Second, we should build as much as our capital allow us. And third, we will fill GPUs in line with contracted or clearly visible demand. This massive 80% spend will come only when we see real demand. That’s why we say that in 2026, we will be securing 2.5 gigawatt total contracted capacity. And we are planning to physically build 800 to 1 gigawatt of connected data centers. This will be done by the end of next year.”
Assuming that the 0.9GW they’re targeting by the end of ‘26 includes having the GPUs online, this would mean that the $8 billion ARR roughly translates into $9-10 billion of revenue per GW of GPU capacity. This number is in line with CoreWeave, but below what the major clouds are doing as neoclouds have to discount in order to attract customers. The bull case to increase this number over time would be: 1) increase the number of web services available on neoclouds over time, e.g. object storage, vector databases, potentially nosql databases, etc. to turn their data centers more into a real cloud where enterprises can run an entire app on. 2) Diversify the customer base to move away from large contracts with the hyperscalers and build up a real client base of enterprises and successful AI startups/ winners themselves.
We’ve written extensively about the strengths of the big three clouds, i.e. Amazon AWS, Microsoft Azure, and Google Cloud Platform, and we’ll do a brief recap here for new readers. The attraction is that enterprises leverage all sorts of software tooling on these clouds in order to deploy their workloads in the cloud. As they replace their old, on-premise data centers – due to the large amount of software engineering involved to manage a cloud – they become effectively locked in on these major clouds.
Enterprises try to reduce this risk by pursuing a multi-cloud strategy, however, due to the high amount of software engineering involved, they typically spread their workloads over two clouds. For example, 70% on AWS and then 30% on Azure. This also makes sense from an economic standpoint, as a cloud provider will give you discounts for a large, multi-year contract. So, an enterprise customer wants to have some leverage by deploying 30% on Azure for example, and then also get a large discount from AWS by deploying most workloads there.
Major clouds have the entire software stack available you need to deploy apps. I.e. CPU-based VMs, databases (SQL, Firestore, DynamoDB etc.), data pipelines (Dataflow, Kafka, etc.), data analytics (Fabric, Snowflake, Databricks etc.), security, access management, load balancers, networking, caching databases, object storage, edge network caching, etc. You can see below some of our favorite products we have pinned in our Google Cloud Platform console, which makes it easy to deploy and manage all your cloud workloads:
Very little of this is available in Neoclouds, these are mostly platforms where you can rent GPUs. CoreWeave has built some neat scheduling software so that users can deploy their AI workloads on a fleet of GPUs with near bare metal performance. However, all the larger clouds are extremely good at writing these sorts of abstraction layers. CoreWeave’s Slurm adaptation (SUNK) for example is built on Kubernetes, which was open-sourced by Google and based on Google’s internal orchestration system called Borg. Nebius has built a very similar system as SUNK called Soperator (Slurm operator) and open sourced it in late ‘24. This means that basically any cloud now can adopt a Slurm-on-Kubernetes system like CoreWeave’s. This system basically makes it easy to manage your fleet of GPUs and even switch between training and inference workloads, so that the GPUs never sit idle.

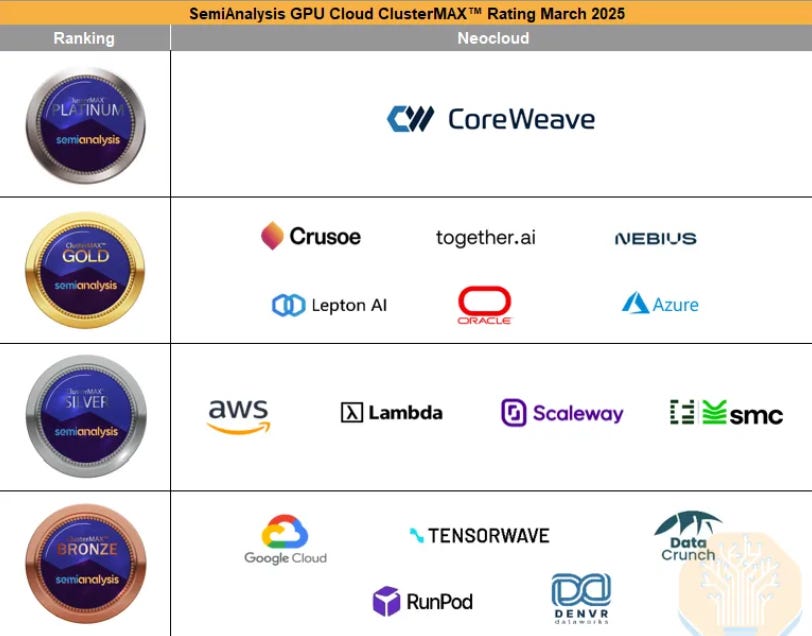
When some investors look at the type of analysis like below, they conclude that – ‘The big three clouds are behind; CoreWeave, Nebius, Crusoe, etc. have the advantage, and as these neoclouds are growing revenues much faster and winning big contracts, the risk-reward is very attractive in these names’. More extreme viewpoints include that the big clouds will get disrupted by these neoclouds. However, SemiAnalysis is purely comparing GPU cluster performance here, and then a lot of investors mistake this as an assessment of overall cloud capabilities.
The reality is that the two types of business are very different. As both types are being labeled as ‘cloud’, this causes confusion as a lot of non-engineers don’t properly understand what’s under the data center hood. Even if you want to run an AI-centric app such as ChatGPT or DeepSeek in the cloud, the reality is that you heavily need one of the major clouds as an AI cloud won’t do. You need access to databases, analytics platforms, load balancers, caching databases, elastic VM services, observability, security, networking, IAM, etc. What you can do on neoclouds is send an API request to the GPU, so that a GPU can analyze your prompt, run this through various linear algebra algorithms on its CUDA cores, and then send back an answer.
Most enterprises take up as much capacity as they can in the major clouds as it allows them to run their GPU VMs alongside where their data is stored. It’s very expensive and time-consuming to move large amounts of data out of these clouds due to high egress fees and bandwidth constraints. This is why winning contracts with the big clouds presents so much upside to the neoclouds, as neoclouds are only gradually winning their own customers. So, most of neocloud revenues are currently coming from hyperscalers where end customers are not even aware that their GPU workloads are being offloaded onto neoclouds. For example, customers connect to Azure over API and these requests are then sent to CoreWeave data centers as Microsoft is short on GPU capacity. This piece of code below shows what an API call looks like:
The only exception here we’ve seen amongst the neoclouds is Nebius. Nebius was born out of the Yandex cloud, and has a more comprehensive software stack available which normally would take a company years to develop (overview below).

Nebius’ new cloud console will look familiar to AWS, Azure and GCP users, although still much more limited:

However, it will be hard for Nebius to compete for these types of workloads with the big three. One of the main problems for Nebius is that the big three have data centers all over the world and even multiples in every region. Nebius has its flagship data center in Finland. So, in Azure, AWS, or GCP; I could run VMs and duplicate my data in Virginia, Ohio and Oregon, thereby offering 100% uptime and low latencies to users across the US. If one of those cloud regions goes down, e.g. Ohio, you still have the others up and running. And as my international traffic travels over Microsoft’s and Google’s premium global backbones, I get low latencies to users all over the world really. You could even host your VMs and relevant services in Asia and Europe as well if you wish. It’s obvious that this is an extremely premium infrastructure both from a software and hardware standpoint, and a massive competitive advantage if you deploy your apps here vs let’s say in Nebius.
CoreWeave is well aware that these types of software services can increase customer lock-in and bring in high-margin revenues for the company. From the UBS conference:
“We are continuing to innovate right? We are developing new products and services that fit within our AI cloud and what customers will increasingly need in the future. Take things like AI object storage, that’s a product that fits into our broader storage business and that we announced in the third quarter, and has grown to north of $100 million of ARR. It’s growing like a weed. We are deeply entrenched with our customers on a technical level and we understand what their pain points are. We used to live in a world where you were a single cloud customer, an AWS customer. I think you are now increasingly an AWS customer, and an Azure customer, and a CoreWeave customer. Storage was not built for that world. You had data lock in, you had high latency, and if you want to move it to another cloud, you had high egress fees and transaction fees. We built a product that’s low latency with no egress or transaction fees, and customer adoption and attach has been very attractive. We are going to keep building those types of products and services.”
In terms of these types of service offerings, CoreWeave looks to be quite a bit behind Nebius. Object storage is nice but it’s really the most basic of all the web services. It’s one of the very first services that AWS launched 20 years ago. However, a bull case would be that CoreWeave, and also Nebius, can keep building out those types of software services to get access to high-margin revenues besides pure GPU rental.
For premium subscribers, we will dive further into the economics of neoclouds such as Nebius and CoreWeave, including with some detailed financial modeling. We’ll give our thoughts on whether these are attractive investments, and how we are positioning.