
HBM & DRAM Outlook + Software & AI
Semis & Software

HBM & DRAM Market Outlook
The DRAM market has always been extremely cyclical. To make matters worse, this also used to be a highly competitive market resulting into terrible profitability in the 2000s. Despite the boom in gigabytes of DRAM shipped over time, dollar revenues in 2014 were still the same as during the DRAM supercycle of the early 90s:
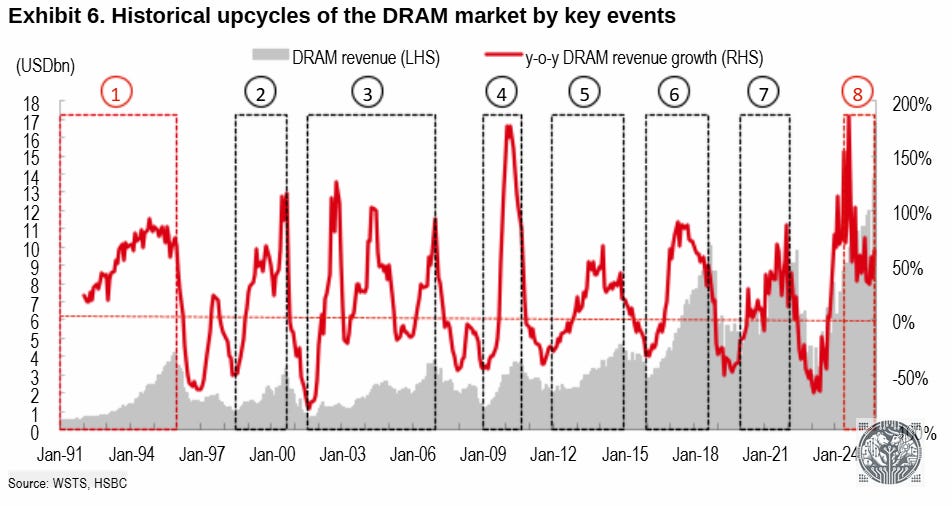
Moore’s Law was a big factor here—basically the dollar per GB dropped by a factor of 10 every 5 years:
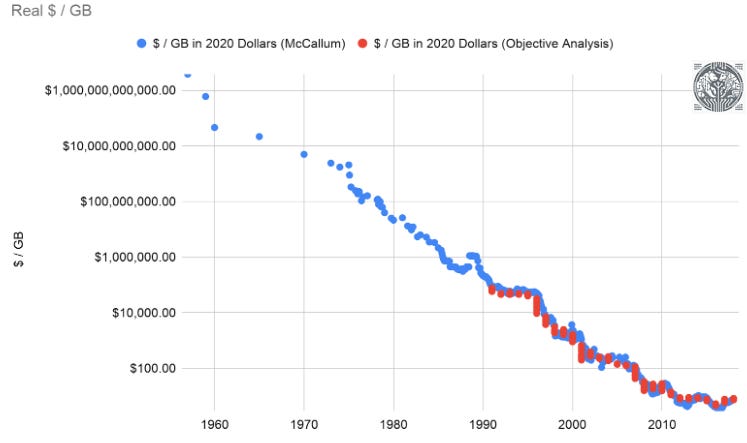
The other factor was a highly competitive market. Too many competitors vying for market share in a commodity-like market resulted in aggressive pricing and low margins. This situation improved dramatically in the early 2010s with the three player oligopoly—that we still have today—finally emerging:
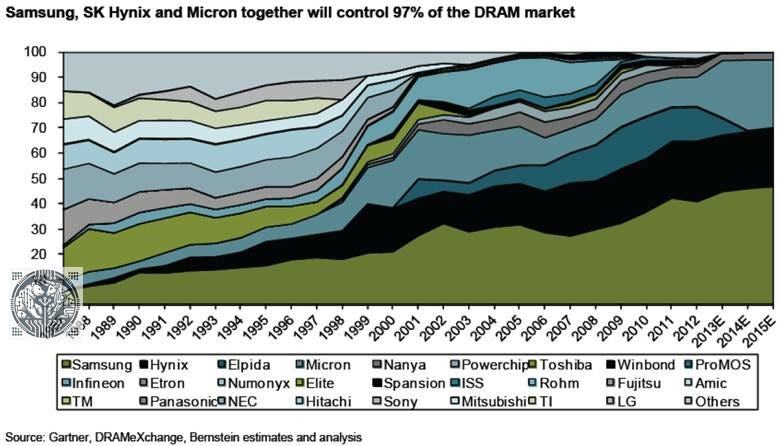
In those days, the memory names were still dealing with a large stigma from investors. Around this time, we actually started arguing that DRAM names had become investment grade due to this three player oligopoly combined with a long term attractive demand outlook, which turned out to be reasonable as this is when Micron’s EPS started taking off. However, the industry remained highly cyclical and so investors had to time when to enter and hold these names:
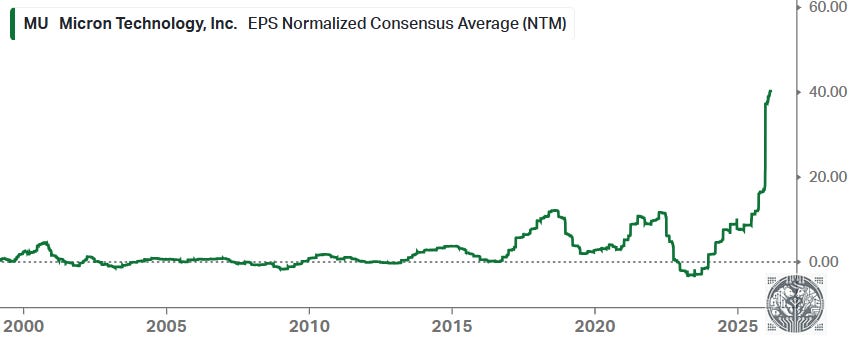
Improved EPS were driven by more disciplined pricing, which resulted in more attractive margins compared to the 2000s:
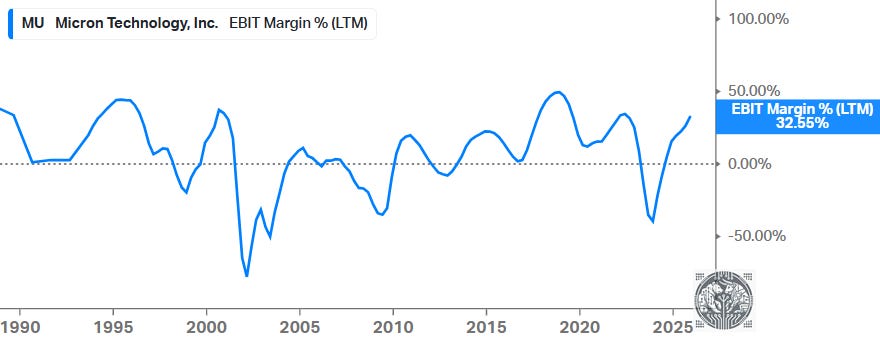
As we know that the memory industry has historically been very cyclical, and with share prices having exploded over the last few years, a rational investor might argue that it’s time to lock in profits now, wait for the inevitable multi-year downturn, and then retake a position once we start seeing new green shoots emerge.
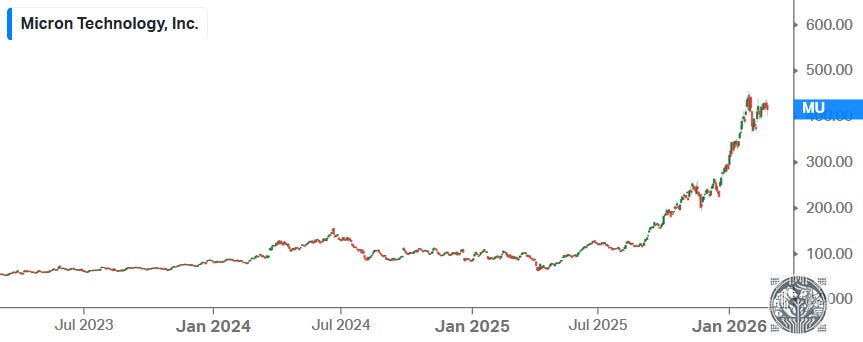
The counterargument is that we’re still in the early stages of an AI supercycle. The annual data center GPU market is still measured in the millions of units, whereas one can start thinking about future AI capacity measured in the number of GPUs per knowledge worker. I.e. each knowledge worker will need x agents, and those agents will need their own agents etc. Software engineering is at the forefront of this trend—despite the marginal cost of writing 500-1000 lines of code effectively having dropped to zero, the demand for software engineers continues to increase.
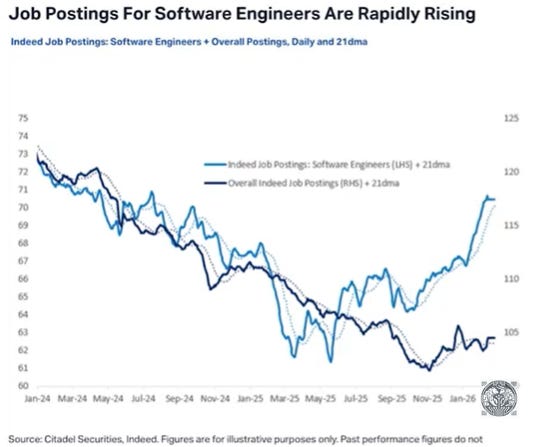
Thus, we’re moving into a scenario where agents are writing out large parts of the code base, and then skilled engineers are needed to instruct the agents how to write the code—i.e. “use this database with this database schema”, “use this type of data structure” etc.—and to then review the code to make sure it’s robust.
There are one billion knowledge workers on the planet, which means that the future AI data center market will very likely become much larger compared to today. It’s well possible we’ll move to an annual data center GPU market measured in the hundreds of millions of GPUs vs the ten million we’ll be doing this year. And then if AI can successfully get inserted at the edge, i.e. robotics and automation, we’re also going to need a lot of GPUs for edge compute, both for training and inference.
Currently, the market is pricing in that we’re at the peak of the investment cycle for key AI names. For example, looking at forward PE ratios—Nvidia is at 22x and Micron is at 10x. Also the sell side is modeling in moderate growth as from ‘27-28:
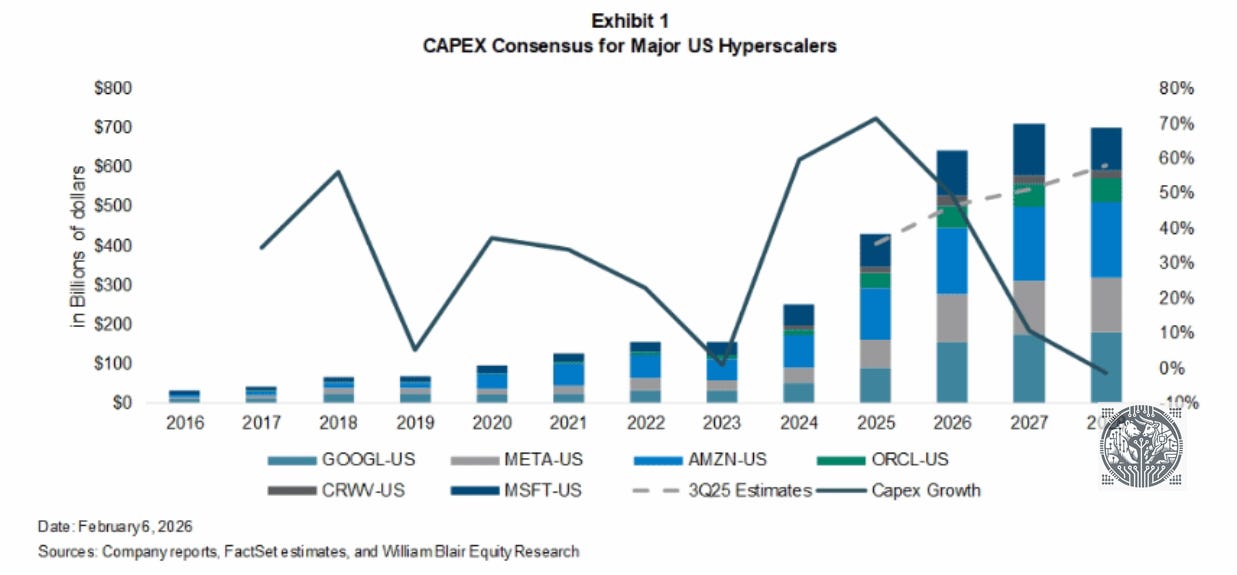
Thus, both the buy side and sell side are saying “we’ll be peaking soon in terms of AI investment”. This is by looking at market valuations and estimates. However, even the DRAM supercycle in the early ‘90s lasted four years, while it looks very likely that the current AI supercycle will far surpass that:
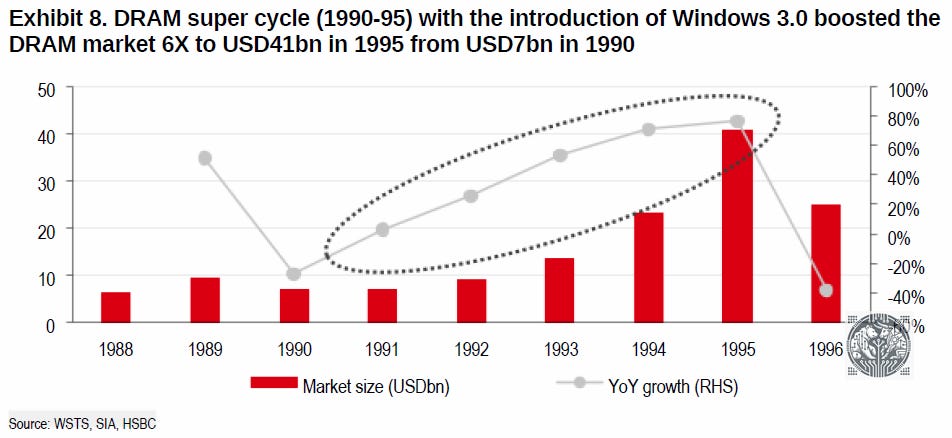
So, this is why we think that Jensen’s long term forecast of $3-4 trillion of AI data center capex could actually be realistic.
James Schneider
Jensen, you’ve previously outlined the potential to get to $3 trillion to $4 trillion of data center CapEx by 2030, which implies a potential acceleration in growth rates, which you’ve sort of guided to at least this next quarter. Do you still feel good about that $3 trillion to $4 trillion envelope?
Jen-Hsun Huang
Yes. Let’s back that up and just reason through it from a few different ways. So token generation is at the center of almost everything that relates to software in the future and relates to computing. If you look at the way we use computing in the past, the amount of computation demand for software in the past is a tiny fraction of what is necessary in the future. And AI is going to only get better from here. And so if you think about it, well, the world was investing about $300 billion or $400 billion a year in classical computing. And now AI is here and the amount of computation necessary is 1,000 times higher than the way we used to do computing. So the amount of token generation capability that the world needs is a lot more than $700 billion. We’re going to continue to invest in compute capacity from this point out. Just as a computer has a lot more computation capability than a DVD recorder, artificial intelligence needs a lot more computing capability than the way we used to do software in the past. Now from an industrial level, because all of our companies in the final analysis are powered by software, and the cloud companies are powered by software, and if the new software requires tokens to be generated, and the tokens are monetized, then it stands to reason that their data center build-out directly drives their revenues. And so compute drives revenues. And I think people are increasingly starting to understand that as well.
So, this is contrarian call, but we believe that the market is still far too skeptical on long term AI demand and required AI investment. Token consumption is currently exploding, and this will likely continue for the foreseeable future, and possibly well beyond.
At the same time, DRAM and HBM requirements per GPU are increasing dramatically. We can see that HBM capacity for Rubin Ultra will go up more than 5x vs the current Nvidia Blackwell:
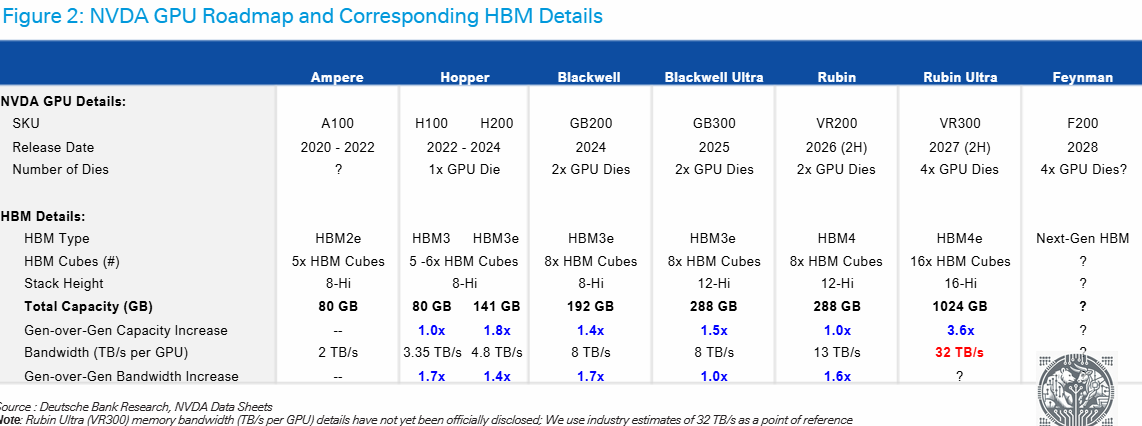
On the supply side, due to the three player oligopoly in DRAM and HBM, capacity additions look to be fairly disciplined, reducing the risk of oversupply. For example, Micron has regularly been telegraphing on their conference calls that they do not seek to gain market share in HBM beyond their current market share in the DRAM market. So, we can see that in HBM, all three players are gradually adding capacity, with not any player looking to dramatically upset the balance in the market:
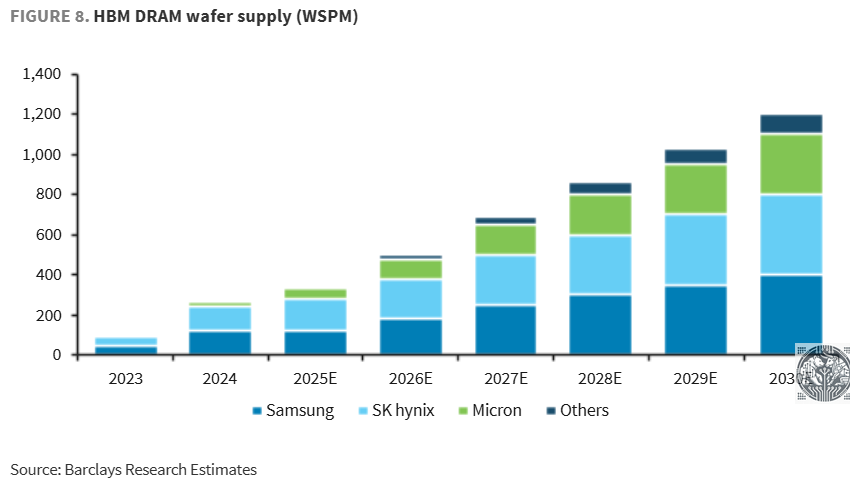
And as the DRAM industry is focused on building out HBM capacity, which remains the key bottleneck when it comes to memory and AI, DRAM capacity expansion will be much more limited:
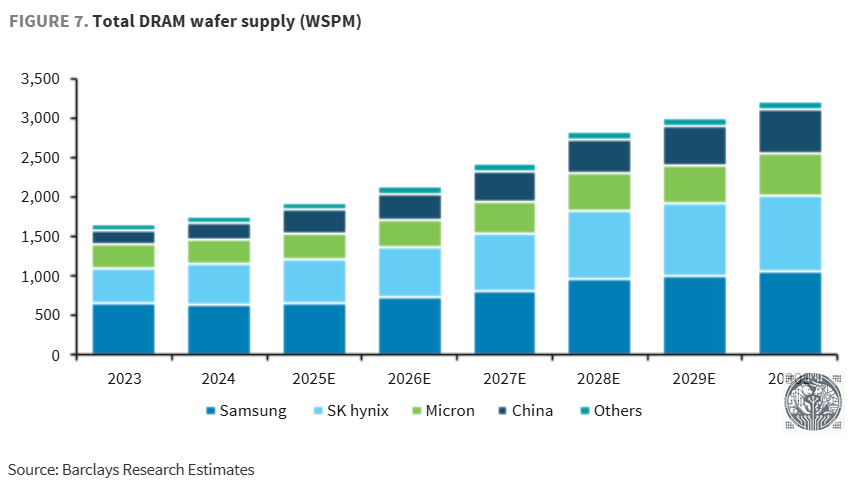
This is Micron’s CFO at the recent Wolfe conference explaining that node transitions won’t be sufficient to meet demand, and that the trade ratio of HBM vs DRAM in terms of needed wafers will continue to go up:
“Traditional node transition is still the most efficient way for us to bring on supply, but those node transitions are less efficient than it used to be. There’s simply not enough ability to produce enough supply out of a node transition. Adding to the supply challenge is the increase in high-bandwidth memory, which is more silicon intensive. And that trade ratio, 3:1 historically for HBM3, that is increasing over time as we go to HBM4, 4E and 5. So, that trade ratio expands and further pressures supply. With that backdrop, we see supply-demand tightness beyond ‘26. We’re committed to our investment plans to invest in a disciplined way to supply customers what they need over the long term.”
We don’t believe that investors should worry about Chinese capacity for two reasons. One, Western hyperscalers won’t source Chinese DRAM anyways for obvious geopolitical reasons. But, secondly, because China doesn’t have EUV (from ASML), as well as advanced immersion tools (from ASML again), their DRAM won’t be competitive anyways with those of the big three. So, we think that Chinese DRAM suppliers will be purely focused on supplying the local market.
Where China could be a threat is if all the Chinese smartphone makers start sourcing local DRAM, this would basically take a chunk out of the big three DRAM manufacturers’ historical customer base. However, the data center market will be the key driver for Memory stocks, and Chinese competition won’t be able to make a dent here.
While all three players are now constructing new fab shells, should demand disappoint at some stage, filling these shells with semicap equipment can be halted. You don’t have to fully fill a fab if demand isn’t there and you can limit the number of manufacturing lines. This limits risk during a cyclical downturn as capex can be reduced again. Overall, we see the profitability outlook in DRAM and HBM as still being attractive with both markets likely to remain supply constrained for the foreseeable future.
Then, the next question becomes which stocks to pick? While we’ve been invested in both SK hynix and Micron, SK hynix remains our top pick. The reason is simple—SK hynix has been executing extremely well as the leader in HBM and they will retain a dominant share with Nvidia Rubin, from UBS:
“We forecast HBM shipment to reach 19.0bn Gb for 2026, up 51% YoY, and for 2027 26.3bn Gb, +38% YoY. This leaves SK Hynix with a bit market share for HBM of 53% in ‘26 and 49% in ‘27. We continue to forecast SK Hynix to maintain close to 70% share for HBM4 for Nvidia’s Rubin in 2026, and first source status for Google’s TPUs. In general, we see all major AI accelerator vendors trying to move by ‘27 to a 3-supplier status. This explains some of the slight market share erosion we forecast, whilst management will continue to aim for 50% share. On the other hand, it may open market share opportunity at AMD and Meta, where SK Hynix is currently not supplying.”
To be clear, we think all three DRAM/HBM names are fine. As from this year, Samsung Electronics’s profits will become heavily dominated by Memory as well, so the company is becoming less of a conglomerate and more of a DRAM/HBM pure play like the other two.
However, as the company clearly executed less well in HBM and in their leading edge foundry—where they’ve fallen far behind TSMC in terms of orders and capabilities, with this division actually making losses—we continue to prefer SK hynix. Although also Samsung’s foundry story is improving, Jefferies notes that the business should become profitable as from 2027 driven by AI demand:
“In 2027, SEC’s Taylor plant is expected to begin mass production of AI5 (50% vender share) and AI6 (100% share) chips, which are the “brain” chips in Tesla’s Optimus and FSD. Tesla should account for 3% of SEC’s Foundry revenue in 2027, 20% in 2029 and 30% in 2031. Foundry should see order receipts jump over 100% YoY, while utilization rates improve on increasing orders from AI data centers and HPC firms, and growing AI chip shipments to Tesla. As a result, Foundry should turn around from a KRW7tn loss in 2025 to a profit in 2027.”
There have been substantial concerns in the market that Micron dropped the ball with HBM4, with their design choices potentially resulting into insufficient pin speeds. However, Micron’s CFO dispelled those concerns at the recent Wolfe conference:
“Since our last earnings call, our business outlook has strengthened further. Demand is significantly higher than our ability to supply and the industry’s ability to supply. We continue to expect supply/demand to be tight beyond ‘26. We are doing everything we can to plan and invest appropriately for our customers’ needs. We’re making good progress on multiyear agreements with specific commitments. We are preparing clean room space that will come online over time, and that will give us the ability to grow our bit supply in line with market demand.
And let me address some recent inaccurate reporting by some on our HBM4 position. We have been in high-volume production on HBM4. We’ve commenced customer shipments of HBM4, and we see shipment volumes ramping successfully this calendar Q1. This is a quarter earlier than we mentioned during our December earnings call. Our HBM capacity is ramping well, and we have sold out our calendar year ‘26 HBM supply as we highlighted a few months ago. Our HBM4 yield is on track. Our HBM4 product delivers over 11 gigabits per second speeds, and we’re highly confident in our HBM4 product performance, quality and reliability.”
So, the market is now pricing in a cyclical peak given the low valuations these key AI names are now trading on—22x PE for NVDA and TSMC, and even 6x for SK Hynix:
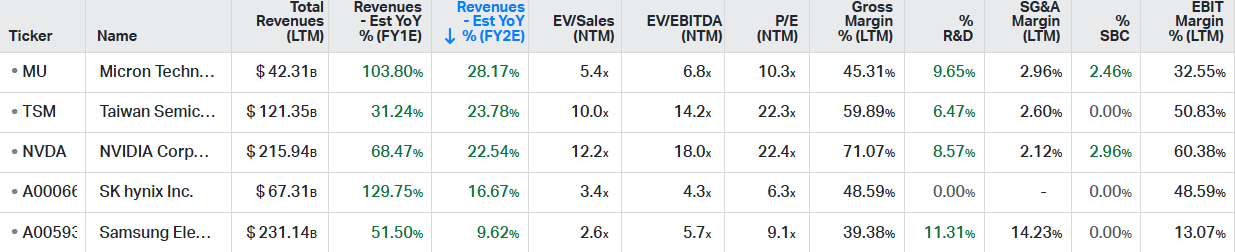
Actually, these stocks have been climbing a wall of worries over the last three years. Consistent fears of overspending and an AI bubble forming have weighed on valuations for these names for the last three years really. All share price performance basically has been driven by EPS growth:
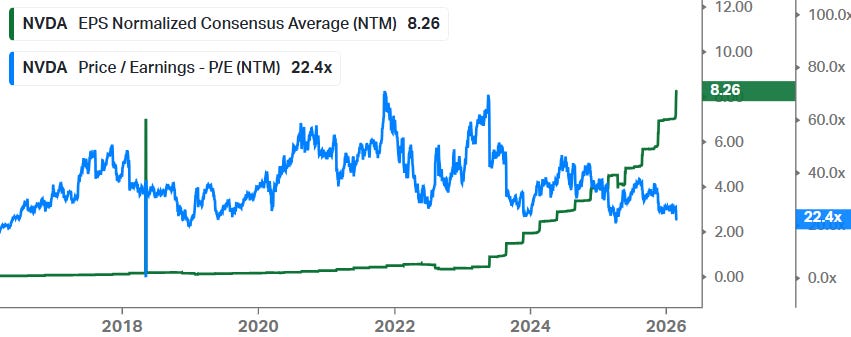
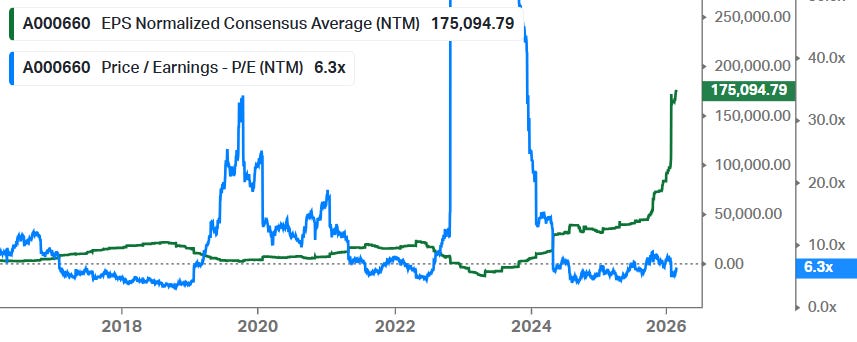
Given how our own token consumption continues to dramatically move higher, as well as enterprise token consumption in the cloud, we continue to be bullish on the growth in AI applications over the coming 3-5 years.
Tech, Semis, and AI are currently exploding in China. Wouldn’t it be cool to listen to all those tech podcasts by Chinese LLM builders—such as DeepSeek, Kimi and Qwen—and understand the latest innovations?
Our friends at Lang Dojo have built a great course to learn Chinese fast. We’re impressed by how fast we’ve learned to read Chinese characters and understand spoken Chinese after studying the course.
If you like to learn Mandarin Chinese, check out the course on the link below, which includes free lessons and video lessons:

Software Outlook & Stock Picks
We outlined a few weeks ago our bull case for the software industry and recently HSBC published their deep dive covering the intrinsic characteristics of software, which many investors are not familiar with. Their reasoning and arguments are similar to the piece we published, and we highlight the key points of their analysis below:
“The software sector is likely to be a net beneficiary of the AI revolution. Market concerns that AI will replace enterprise software are misplaced in our view. LLMs and vibe-coding agents have been trained on public, not private, data and thus, don’t know the optimized large scale high-fidelity architectures. Thus, the burden of developing a competitive platform would be left to the coders who don’t know the private innerworkings of these complex mega large scale platforms. Even if you have great code, you need to demonstrate years of five 9s+ of uptime; error-free operations, and robustness across a highly diverse set of customer IT environments. Competing effectively in the mission critical enterprise software sector is difficult as one needs an enterprise class sales force, trusted brand, and large referenceable clients to gain trust.
We see AI as the primary source of value creation of the software stack, with the largest share of long-term value accruing to software rather than hardware. This is similar to the evolution of the internet; the early attention was on deploying physical infrastructure, such as PCs, fiber, and servers, but once that foundation was established, the real value shifted to the software sector. In the same way, we see the current AI narrative dominated by hardware build-out, but we expect this phase to be transitory. We believe the value of AI lies in how it is embedded into software applications that reshape workflows, decision making, and productivity. We believe the AI ecosystem will follow a similar trajectory.
We believe agents will be the primary monetization layer for AI consumption. Rather than generic chat interfaces, enterprises will deploy task-specific, workflow-embedded agents designed to provide a controllable and governable framework for AI adoption. Notably, this allows enterprises to ringfence usage and manage risks where hallucination can be handled programmatically in well-defined parameters. We expect inference demand to exceed training demand over time, driving sustained growth in compute requirements. Overall, we believe that as agentic AI becomes pervasive, usage intensity increases, driving token consumption.
Is there a widespread misunderstanding of AI and software? We have been talking about the topics in the software space for over two years, and nothing new in these topics causes us to deviate from our previous conclusions. And these conclusions align with Nvidia’s Jensen Huang’s recent comment that AI replacing software “is illogical”. However, the negative AI versus software headlines continue and, to us, there seems to be a herd mentality behavior developing around the indiscriminate comments regarding the demise of the enterprise software sector. Thus, we wonder if there is somewhat of an echo-chamber forming in the market that is amplifying Mr Huang’s “illogical” scenario? Although we are not certain about the behavior, we do know that there are many media firms and tech companies that make up the market information channel, and each will look for a megaphone to bolster their own worldview. Thus, it is important to keep in mind that many of these pundits put forth a view that places their organization in a favorable light or improves readership and may be self- serving. And their “marketing” may not fully represent an accurate reflection of reality, and a calm assessment of the facts is always recommended.
Will AI write code that will replace legacy software applications? The technology marketplace is an odd thing where the best or cheapest products don’t always win. Software is a business, and there are many success factors that influence how a software business grows, prospers, or fails. And it is important to recognize that enterprise class software is different from simple apps or smaller-scale narrow-focused software programs. Enterprise class software platforms are some of the most complex and have different success factors that determine outcomes within the marketplace. A simple example of a success factor would be first-to-market, as once a large platform application is installed and a customer’s business runs its critical operations on it, switching carries many risks.
One simple, and obvious risk is if there is disruption during a platform replacement, normal operations can stall, loyal customers can leave forever, brands are tarnished, and revenue can hard-stop until the issues are resolved. And a full-stop to a company’s revenue stream would be bad, particularly for publicly traded companies. There are also many other unforeseen switching risks/costs, like lower productivity and numerous process errors as users retrain and become acclimated to a new system. Or the sudden appearance of unwanted feature interactions that only manifest under long-duration at-scale operations in a customer’s unique mega-cluster of other applications (both internally and externally developed). Think of this as a complex system failure where many rare events converge and result in a system shutdown or in unwanted behavior, like errors. These types of failures are sometimes as tricky to understand as they are to resolve
Furthermore, promised incremental value-add is not always realized and less efficient operations after replatforming are a possibility (i.e., theoretical versus actual). Therefore, in our view, the promise of incremental benefits from replatforming are rarely sufficient to warrant a change. Hence, once a vendor platform is installed, persistent vendor lock-in is a common outcome. And looking at the competitive history between SAP and Oracle on the ERP front is a reminder of the difficulty in replacing platforms and how replatforming can fail. A high-profile example that even cheaper/free solutions may not be enough to displace an incumbent vendor is Microsoft’s Office suite. Competitors like Google and Apache OpenOffice have not materially displaced Microsoft’s Office Suite in enterprise, despite offering free office-like suites for decades. There have also been concerted efforts in the past to displace Oracle’s high performance database business by Microsoft, Amazon, SAP, and CRM, with minimal success.
And there are many other technology examples like VHS versus Beta or NTSC versus PAL that have all evolved with inferior technology coming out on top due to numerous other factors. Thus, just because AI can write code does not mean that that code will be competitive or widely adopted, even if it was given away for free. India-based companies have had the ability to create and market enterprise class software for decades at scale. Yet over the decades, even with this insight and a massive low-cost skilled workforce, no regional vendors have successfully emerged to challenge the legacy US vendors. Factors such as enterprise class sales teams, technology cross-licensing agreements, proprietary and patented IP, industry specific domain expertise, aligned workflows with industry practice, first-to-market, brand awareness, scale, or effective go-to-market strategies are just the tip of the iceberg when looking into the key attributes needed to compete effectively in the software sector. Just making code is not enough.
Moreover, wishful AI competitors are using models that were trained with mostly publicly available data on the internet. And although snippets of code are available on the web for AI to learn from, large complex enterprise class system code and proprietary IP are private and are largely not available for training foundation models. Deeply complex code that incorporates business logic, proprietary IP, and private client data are viewed as prized assets by legacy vendors and are typically vigorously protected. And between state-sponsored industrial IP theft, employees moving from competitor to competitor over their careers, and malicious hackers, key aspects of platform designs may be as protected as the formula for Coca Cola.
The actual code generation is only a small part of what it takes to be a successful competitor. In other words, you would need to become an enterprise class software company, with all of its complex business skills and IP. And the key success factors necessary to succeed and compete effectively are grown over time. Meanwhile, there are existing companies with all of the attributes, private information, scale, and vibe coding skills needed to leverage AI’s potential. That is, the existing enterprise class software companies themselves, the same vertical that market conjecture is questioning its staying power. These platform players don’t need time to mature and grow into becoming an enterprise class software company, they are enterprise class software companies now, and they have been aggressively working to leverage and embed AI into their global platforms.
Moreover, we think that most of the legacy platform vendors have spent much of the past two years designing and training intelligent agents. We believe they have been creating these expert agents through a domain-specific fine-tuning process using both private internal and client data. And they have just begun public releases of initial AI platform updates that include embedded agents. Therefore, through this process, we see the enterprise platform vendors as the dominant diffusion mechanism for leveraging AI in the world’s largest enterprises. Yes, some companies will build less complex internal apps and custom software for some tasks, but for the complex infrastructure that creates and runs the world’s commerce, we think that remains captive to the platform players. And we think that many of our Buy-rated software companies will, in fact, thrive to new levels.
The software model and the price vendors charge is highly correlated and dependent on the value proposition of their offerings. This is why a large price can be commanded for software, even with a minimal marginal cost of production. Thus, in dominating AI’s primary diffusion path (i.e., the continuing infrastructure providers of the Global 2,000), previously unthinkable TAM expansion for the enterprise software vertical is happening, in our view. We see this as a rapid and significant expansion in TAM and the software vendors responsible for unlocking this value will have claim to its share. And just as software unlocked most of the value in the internet, enterprise software is set to unlock most of value in the AI ecosystem, in our view.”
Next, we will dive into stocks that we see as AI beneficiaries in software. The space has been engulfed in panic selling over the last months, which usually opens up tremendous buying opportunities for long term investors. While there will be no quick fix for software names, we do believe that software companies that can show revenue acceleration and margin expansion over the coming years, that this will lead to strong share price outperformance given the current cheap valuations.
Basically, software names that can show that they’re AI winners by embedding AI agents and automation inside their platform, and translate this token consumption into revenue monetization, the market should reward those names with higher multiples. This is also what happened with Google. After the successful launch of the latest Gemini model, combined with their progress on the TPU side, this led the market to rethink its view that Google will be an AI loser, and the market then decided to reward Google with a much higher multiple. Combined with growing EPS, this led to strong outperformance with the shares doubling in less than a year.