

Training vs Inference Silicon
Nvidia has so far taken the bulk of the market in AI acceleration, however, as silicon becomes more specialized based on the workload, this provides an opening for competitors to grow share. A research engineer at DeepMind (Google) explains why the market is likely to bifurcate into training vs inference chips:
“One concept that is relevant to think about here is this idea of whether your computation is what we call compute-bound versus memory-bound. So whether you need to be able to execute more flops in order to go faster. When you're doing a reasoning model, it's more memory-bound. The reason is that it's inference applied on top of inference in order to generate chains of thought. Because you're doing that, it's more memory-bound. The core idea there is that when you're doing training, it's just one forward pass and one backward pass. That's the intuition behind why training is very compute-bound. If you are able to use the latest NVIDIA architecture, you will be able to go faster. With each generation of chips, the number of FLOPs grows at a faster rate than the amount of memory you can move. And it's a lot easier to innovate on doing more FLOPs than it is to innovate on moving memory faster.
Thus, when you're in training, that's compute-bound and so the latest and greatest chips allow you to go faster. When you're doing inference, you're only generating one token at a time. You're doing a lot of forward passes. What that means is, you're also moving a lot more memory around as opposed to doing a lot of arithmetic on one piece of memory like you do in training. For that reason, you are memory-bound in inference. So if you want to go faster, having a more computationally powerful chip isn't going to do anything for you. You need a chip that can move those bytes around faster. The GPU can be just sitting idle, waiting for memory to come in for the next token to generate.”
So in inference, you have to pull all the model weightings into the chip from the HBM as you have to do a lot of matrix multiplications of your input with these model weightings. Whereas when you do the backward pass, you have to calculate the gradients of these weightings as you will have to adjust them in order to train the model. This second workload is computationally intensive, whereas pulling in model weightings is bandwidth intensive. So there is a case that leading silicon will become more specialized to handle inference vs training workloads, as you need more bandwidth in inference and more FLOPs in training.
Another factor is that not all inference will have to be on leading silicon, as simpler tasks can be done with less advanced chips. This is again the research engineer at DeepMind.
“Right now, state-of-the-art chips are being pushed. Once we get this capability overhang and maybe we're already there—where an accountant doesn't need GPT-five to do their work—then you can do a lot of the inference that's required on cheaper hardware, especially if you're in a domain where you don't need extremely fast responses. Google will always care about buying the latest and greatest inference hardware, but companies rolling their own stack won't care about that. So Huawei chips, the fact that they caught up to 60% of inference performance or something like that, that's probably totally fine for a lot of workloads. Unless you're trying to build a company like Google or you're trying to be able to serve these models at ByteDance-level scale. Those types of chips won't be sufficient for training the next frontier of models.”
We’re still in the early stages of AI, probably at a similar stage like we were in 1996 in the internet revolution. Where we saw in subsequent decades new waves of innovation being built on top of this new technology—search, SaaS, social media, the public cloud, and finally AI, due to the availability of massive amounts of data from the internet to train models. So far, Nvidia has taken the bulk of the market and this is logical. Companies who want to become a player in AI have to move fast and so you buy the best stack, which is also the stack that is already fully functional and optimized.
This is not new—in the early stages of a new technological revolution, there usually is one vertically integrated company that is really at the center of the new wave of innovation. We saw similar patterns in cellphones (Nokia), smartphones (Apple), electric vehicles (Tesla), PCs (Microsoft), mainframes (IBM), etc.
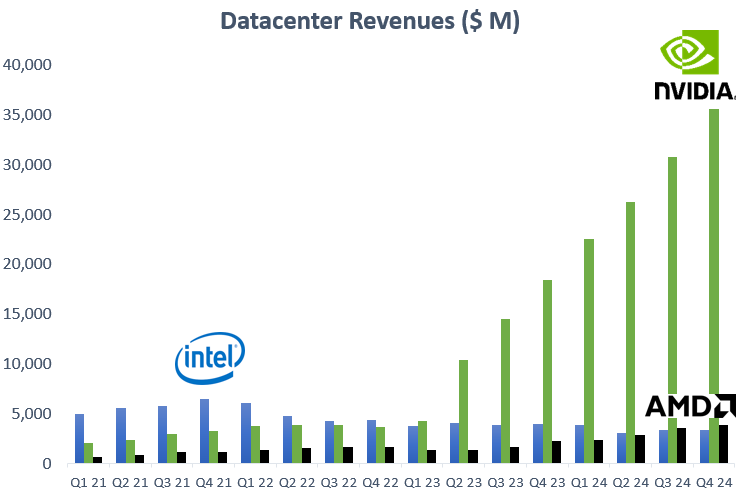
However, over time, a number of players that have the availability of a sufficiently large budget to compete in leading edge silicon design, together with the hardcore software engineering skills, will be able to get a stack together that’s fully functional. A good example here is Google, which already has a competitive stack ready with their TPUs, XLA (Google’s answer to CUDA) and JAX (Google’s answer to Pytorch). Similarly, as the inference market becomes dominant in the coming years, more companies will be looking to offload AI workloads on more cost effective silicon such as ASICs and potentially also AMD.
Amazon’s Roadmap in AI - ASIC Suppliers & AI Demand
Amazon acquired Annapurna Labs, an Israeli startup, in January 2015 for an estimated $350–370 million. Prior to the acquisition, Annapurna Labs had been collaborating with AWS, contributing to the development of the AWS Nitro System. Nitro includes specialized Data Processing Units (DPUs), designed to offload tasks from Amazon EC2 instances (compute servers) in the cloud, enabling EC2 to achieve a performance close to bare-metal. An example here is offloading virtualization workloads from the host CPU to dedicated hardware. Due to their massive scale as the largest cloud provider globally, Amazon has been a key player in specialized hardware to optimize cost-performance ratios for their data centers. This is a manager at Amazon giving the philosophy behind their strategy:
“In terms of hyperscaler customization, we are one of the leading companies. Google's TPU is the only exception there, they’ve been there longer. In terms of customization, the philosophy is two-fold. First, we need to have economies of scale and enough volume. That's the reason why we first started with the so-called Nitro Card because it's in every single AWS instance, and we add millions of servers each year. Second, we started with a Graviton ARM-based CPU. Now, it's public information that 50% of our new CPU additions each year is Graviton replacing the x86 architecture. Thirdly, we're starting to do accelerators. These chips are already in the millions each year, so we have the scale.
Now, these accelerator chips are extremely difficult to make. Going forward, it's close to $1 billion of investment for each generation in terms of all resources and licensing. We haven't really ventured into customizing the networking components yet, it's semi-custom. We work with some companies to semi-customize a network chip, and there's other custom stuff in the works. For example, we have announced a partnership with Intel to work on using the 18A process. It's definitely not the Trainium chip, some of the smaller ones. These chips, we do semi-custom but we don't expect them to be high volume.
Another criteria to customize is whether we can do better and gain a proprietary advantage with the silicon. An example is a silicon photonics chip we co-developed with STMicro, the PIC 100. It's semi-custom for us so we can lead in the 800G and the 1.6T architecture in optics. We actually prefer to work with smaller suppliers which are more nimble and more willing to help us customize and grow with us. This is a typical philosophy, especially for a fast-growing category. That's the reason why we picked Astera Labs for example. So these are the two criteria to customize silicon—one is economic scale and second, whether we can do it better and achieve a lower cost than other common solutions.
Annapurna Labs developed our Arm-based CPU which is Graviton. We are at the fourth generation now. This product line, we have staffed end to end. We pretty much don't outsource any of the R&D effort or manufacturing management. About three, four years ago, right before GenAI started, Amazon Annapurna started a project on the accelerator. We saw the success of the Google TPU and that AI workflows are going to be a big thing. It started with an inference chip, the first generation is called Inferentia1. Then we started to build training chips called Trainium. Trainium first generation is the same platform as Inferentia2. So now, Trainium2 is on the same platform as Inferentia3. We're at the third generation of our accelerator. ”
For premium subscribers, we will dive deeper into current developments in AI silicon. Key topics will include Amazon’s plans in ASICs and which design partners they will be working with going forward, as well as what they’re seeing in AI accelerator demand. Second, history and background of the key players in ASIC design, and to what extent hyperscalers are planning to take this business in-house. Third, developments for AMD and the company’s strategy to gain share in AI. Fourth, the future of LLM architectures and the implications for AI silicon. Finally, we’ll review valuations and financials for key players in the space with our stock picks.
An interesting topic is with which ASIC designers the hyperscalers such as Amazon will be working with and to what extent they can bring these activities fully in-house. Similar to how Apple has been taking their silicon design in-house for CPUs and going forward also for wireless silicon. This is the manager at Amazon on how they’re thinking about outsourcing chip designs and which suppliers they will be working with in the coming years: