
Cerebras Deep Dive
Disaggregated Inference, Wafer-Scale Engines, The OpenAI and Amazon Deals, IPO Thoughts

Disaggregated Inference—The Amazon Partnership, Benefits vs Drawbacks
Cerebras accelerators have a radically different design than current XPUs. Instead of dicing a 12-inch silicon wafer into dozens of individual chips, Cerebras leaves the wafer intact to create a single, gargantuan processor. The current iteration, the Wafer-Scale Engine 3, is fabricated by TSMC on a 5nm process featuring 4 trillion transistors distributed across 900,000 AI compute cores.
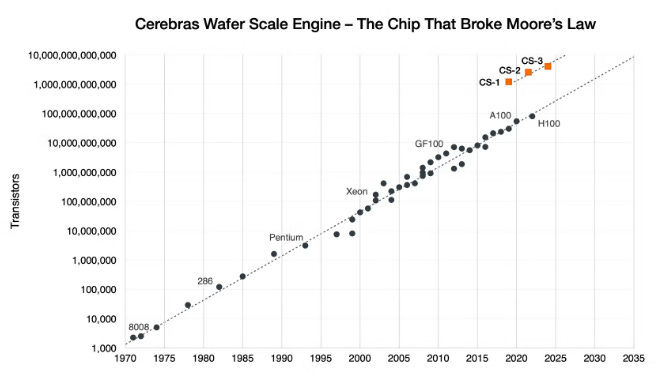
Its wafer scale accelerator is 57 times larger than a single Nvidia B200 die:

This monolithic design addresses the primary bottleneck in LLM workloads: the memory wall. By keeping 44 GB of SRAM directly on the wafer, Cerebras’ WSE delivers a massive 21 petabytes per second of memory bandwidth, resulting into much faster inference (up to 15x according to the company compared to Nvidia B200):

For a GPU to calculate the next token, it needs to multiply the current state by the model’s weights. Because of how autoregressive decoding works, you cannot process the next token until the current token is finished. So, to generate one single token, the GPU must read the entire model from its VRAM (HBM) into its compute cores. Because the GPU is doing very little math per byte of data moved, this means decoding is memory-bandwidth bound. Cerebras’ design minimizes this bottleneck by storing the model weights in SRAM, which is located right next to the compute cores.
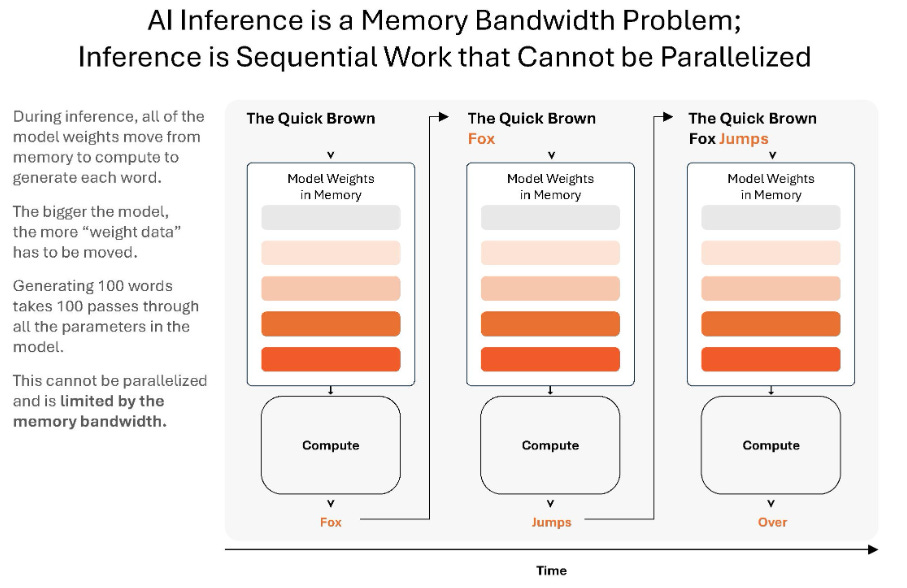
Nvidia is aware of the massive bandwidth advantage of SRAM, and so recently announced a unique inference solution that combines the best of both worlds—Rubin for the prefill and the attention phase of decoding (which are compute heavy) and Groq for the final token generation phase of decoding (which is bandwidth intensive). In the first phase, handled by Rubin, the AI figures out what the prompt and its context (stored in the KV cache) are about. While in the final phase, handled by Groq, the model applies its learned knowledge (i.e. its parameters or weightings) to the specific query:

A key drawback of SRAM-based inference systems like Groq and Cerebras is that SRAM doesn’t have much memory capacity. So, you have to connect 45 Cerebras CS-3 wafers together to hold a 1 trillion parameter model. Cerebras can technically cluster up to 2,048 wafers together, so even a state-of-the-art 10 trillion parameter model fits well within this theoretical maximum.
The KV cache stores all the context from the user queries and so takes up a lot of memory. This is why you want to network together an SRAM-based system with a classic XPU server which has loads of HBM, DRAM, and even SSD. As context windows get longer and longer with AI agents doing multi-turn reasoning, the KV cache explodes in size. It quickly exceeds what fits in HBM, and even DRAM. As having to recompute the KV cache is compute expensive, this is the reason why Nvidia recently added additional SSD to their servers. This is also the reason why pure SSD stocks rallied strongly last year, however, this is a commoditized and competitive industry, so make sure you don’t hold these bags for too long.
The second drawback of a Cerebras inference system is the high price tag. While it can hold a 1 trillion parameter model and more, networking a 45 Cerebras CS-3 cluster together can easily cost $100 million or more. For comparison, a single Nvidia GB200 rack can hold more than six of these models in its HBM at a hardware cost of only $3.5 million. The advantage of Cerebras is low latency, whereas the advantage of Nvidia is loads of memory. A single Nvidia rack has so much memory it can handle queries from tons of users at the same time, perfect for a chatbot app or a LLM API. Cerebras is more like a Formula 1 car that provides ultra low latency inference for a user willing to pay up for it, e.g. Citadel hedge fund or Goldman’s trading desk.
So, Cerebras has two key problems—firstly, a lack of context memory, and secondly, an astronomic price tag.
The first problem, a lack of context memory, can be solved when you combine the Cerebras system in a disaggregated inference solution with a traditional XPU server which does have the memory. As Nvidia has already shown, you get the best of both worlds—loads of memory and fast decode. This is exactly what Cerebras is now doing with their new Amazon AWS partnership:
“We signed a binding term sheet with Amazon Web Services for AWS to become the first hyperscaler to deploy Cerebras systems in its data centers. Deployment in AWS data centers will require us to meet strict standards for performance, scale, and reliability. Pursuant to the term sheet, we will create a co-designed, disaggregated inference-serving solution that will integrate AWS Trainium3 chips with Cerebras CS-3 systems, connected via high-bandwidth networking, to partition inference workloads across Trainium3 and CS-3. Each system will perform the type of computation at which it most excels. The approach is expected to deliver 5 times more token throughput in the same hardware footprint, at up to 15 times faster speeds compared to leading GPU-based solutions as benchmarked on leading open-source models.
Inference disaggregation is a technique that separates AI inference into two stages: prompt processing, or “prefill,” and output generation, or “decode.” These two stages have different computational characteristics. Prefill is natively parallel and requires very little memory bandwidth. Decode, on the other hand, is inherently serial and memory bandwidth intensive. Decode is typically the bottleneck. It dominates total inference time, and defines the speed of the user experience. Disaggregated inference would allow Cerebras to operate alongside other architectures, serving as the high-performance engine for decode while other systems handle prefill.”
AWS will make this hyperfast inference available via Amazon Bedrock for a variety of LLMs, including open-source models.
The second problem with Cerebras is the very high price tag. This also becomes more manageable in a disaggregated inference solution as the throughput, i.e. the number of jobs and users that the Cerebras servers can handle, gets a large boost as Cerebras’ wafers can now purely focus on serial token generation. If those users are willing to pay a substantial premium for these hyperfast tokens, the investment starts to make sense. This is what Jensen said on the demand for hyperfast inference at GTC:
“At the most valuable tier, we’re now going to increase performance by 35x, and I would add Groq to maybe 25% of my total data center. With the rest of my data center all Vera Rubin.”
So, Jensen has probably provided the biggest bull argument for the TAM Cerebras will be competing in. The second bull argument is that Cerebras looks to be a strong player in this TAM, as the company recently disclosed another interesting partnership…
The OpenAI Deal
“We signed the MRA with OpenAI on December 24, 2025. On January 23, 2026, we began delivering capacity to OpenAI, and on February 12, 2026, OpenAI’s Codex-Spark model, powered by Cerebras infrastructure, was made available to the public. Spark is OpenAI’s model designed for real-time coding. Using Cerebras, OpenAI’s customers can translate ideas into working software in seconds, enabling developers to create software at the speed of thought. OpenAI has committed to purchase 750MW of Cerebras inference compute capacity over the next three years.”
This 750MW deal is worth $20 billion, and so spread over three years, this would be around $6.7 billion in annual revenue for Cerebras. We can work out that OpenAI is basically paying here roughly $27 billion per GW of Cerebras capacity. There is an option to expand the agreement to 2GW by 2030, meaning that an additional 1.25GW can be provided by Cerebras to OpenAI in ‘29 or ‘30. This would mean another $33 billion potential order from OpenAI. OpenAI and Cerebras also agreed to co-design future OpenAI models for future Cerebras hardware.
OpenAI won’t purchase the equipment. Cerebras will provide the capacity in a managed compute-as-a-service type agreement. As Cerebras has to order the required wafers from TSMC, OpenAI also gave Cerebras a $1 billion working capital loan. If Cerebras can deliver the compute successfully, no interest has to be paid. Otherwise the interest rate is 6% on the loan.
Cerebras also issued a warrant to OpenAI for 33.5 million Cerebras shares, with vesting directly tied to equipment purchase milestones. So, if OpenAI orders the full 2GW of compute by 2030, they’ll be given the full 33.5 million Cerebras shares. As the exercise price per share is basically $0, OpenAI has a financial incentive to order more Cerebras compute. The dilution, if this warrant gets fully exercised, will likely be around 10%.
Bears will point to the circular financing nature of the agreement, however, we argue that for a startup it’s not easy at all to get a hyperscaler or leading AI lab to run inference on your silicon. A large AI player will have to make considerable investment to deploy models on your hardware—compilers will have to be written, the equipment has to be tested and verified, software layers have to be coded to automatically deploy models on a variety of underlying hardware, etc. All of this costs considerable engineering hours.
In the meantime, AI is progressing at breakneck speed. While AI labs will want to optimize their hardware, their key focus is on not falling behind in this race. The value of their business will be determined by capturing sustainable market share and revenues. For example, by winning enterprise AI workloads. In order to do this, you have to train differentiated models, like Claude Code. Improving margins by optimizing hardware will be a secondary objective.
Also on an accounting basis, the value of these warrants will be booked as contra revenues in the coming years. From a US GAAP perspective, these warrants are treated as a sales discount, which lowers the net revenue Cerebras ultimately recognizes from OpenAI.
Business Background & Founder’s Letter
Cerebras does not sell standalone silicon—it packages its wafer into a full system which integrates power delivery, liquid cooling and networking; occupying one-third of the space of a standard data center rack. Revenue so far has primarily been driven by sovereign and university supercomputers in Abu Dhabi.
To make it easy to deploy AI models on Cerebras wafers, the company provides a software platform which includes a Pytorch compiler, an inference stack with APIs, and a cluster management system providing scheduling, telemetry, and health monitoring at scale. This is even integrated with the most popular IDE, VS Code, so you can write an AI model with Pytorch in VS Code and then compile it to run on Cerebras.
The management team, led by CEO Andrew Feldman, brings a proven track record. Cerebras’ founders previously established SeaMicro—a pioneer in high-density and energy-efficient microservers—which was acquired by AMD for $334 million in 2012. Feldman subsequently served two years as VP at AMD, after which he co-founded Cerebras. More than 50 engineers from SeaMicro joined Cerebras, highlighting that Feldman can create a cohesive engineering culture. CTO and co-founder Sean Lie has a longer background at AMD and was also an engineer at SeaMicro:
“Sean Lie is one of our co-founders and has served in various roles since 2016, including most recently as our Chief Technology Officer since April 2022. From April 2012 to June 2015, Mr. Lie served as Chief Architect, Data Center Server Solutions at AMD. From March 2008 to March 2012, Mr. Lie served as Lead Hardware Architect of the IO virtualization fabric ASIC at SeaMicro. From July 2004 to February 2008, Mr. Lie worked as a microprocessor architect at AMD in the advanced architecture team. Mr. Lie holds an M.Eng. and a B.S. in Electrical Engineering and Computer Science from the Massachusetts Institute of Technology.”
It is notoriously difficult to get high yields with wafer-scale silicon—a single defect can ruin an entire wafer. Cerebras circumvents this by outfitting the hardware with millions of redundant compute and memory cells, bypassing defective areas dynamically at the manufacturing level. While this solves the yield problem, the resulting systems are extremely capital intensive. A single physical node is estimated to cost between $2-3 million and can draw up to 27kW of power.

From the founder’s letter, this gives useful background on how they’re thinking about the business and industry:
“The first bet: that existing general-purpose processors would not be sufficient, and that what has always been true throughout the history of compute would also be true for AI – that transformative compute workloads require purpose-built silicon. This is what PCs did for x86, graphics did for GPUs, and mobile did for ARM. The second bet: that modifying existing compute architectures would not realize AI’s potential. We would need to build a new computer architecture from first principles, optimized in every way for AI.
At a computational level, AI is a communication-bound problem. The faster compute communicates with memory, and the faster compute communicates with other compute, the faster and smarter the AI, and the better the user experience. The enemy of speed is communication latency. And since communication is thousands of times faster on-chip than across chips, the best way to reduce latency is to keep communication on-chip.
Our answer: build the largest commercial chip in the history of the computer industry. We used the entire wafer for one chip: a technique called wafer-scale integration. Wafer-scale integration allowed us to bring together quantities of compute and memory never before assembled on a single commercial chip and deliver AI at previously unimaginable speeds.
Nobody knew how to yield a chip 58 times larger than the leading GPU. Nobody knew how to deliver power to a chip the size of a dinner plate without melting the motherboard. Nobody knew how to package such a big chip without cracking it. Nobody knew how to cool a chip of this size, with air or water, without the coolant getting warm before it reached the other side.
We delivered our first systems in 2020 and the second generation in 2022. We had built something extraordinary, but the market wasn’t ready. A few visionary customers in supercompute and life sciences saw the potential, but to most of the world, the benefits were not immediately apparent. Change arrived with ChatGPT. Suddenly everyone was talking about AI, and entrepreneurs were extending the art of the possible.
By early 2025, AI was smart enough to be valuable, and people were using AI everywhere. Inference usage exploded. Suddenly, everyone remembered the lesson from Google search: speed produces more satisfied and more frequent users, while even tiny delays significantly reduce user satisfaction, search frequency, and search revenue. The market had shifted. Everyone realized that fast AI is more useful than slow AI.
By the end of 2025, it was clear: fast inference was powering the highest-value workloads. Fast inference was making engineers more productive because fast AI coding agents could write code, edit it, test it, and get a product to market more quickly. Fast AI made lawyers, analysts, bankers, doctors, and researchers more productive than their counterparts waiting on slow insights. For many workloads, Cerebras is up to 15 times faster than leading GPU-based solutions as benchmarked on leading open-source models. In some more exotic workloads, we have been more than 1,000 times faster.
In March 2026, we started a multi-year partnership with AWS to bring fast inference to an even bigger scale through global distribution. This is planned to give every startup, AI native, and enterprise company easy access to Cerebras’s blisteringly fast inference.
We were among the first semi-conductor companies to have a cloud business. We deliver hardware on-premises to customers concerned about data security and sovereignty. And we reach other customers through the cloud – both the Cerebras cloud and soon the AWS cloud. This allows us to reach customers who want to rent compute by month, year, or to pay by the token, and provides Cerebras with an attractive mix of recurring revenue as well as lumpier hardware revenue.
The fundamental building blocks in computer architecture are calculation (cores), the storage of results (memory), and the movements of results to where they are needed (communication). Our inventions are blurring the lines that have traditionally forced tradeoffs between memory capacity and speed. And the massive size of our processor serves as a foundation for pioneering communication techniques that are only available to wafer scale solutions.”
Financials
The current financials are nothing to get too excited about—the company mainly derives its revenues from AI compute in Abu Dhabi while due to the heavy R&D investment, the business is operating on sizeable operating losses (-40% EBIT margins):
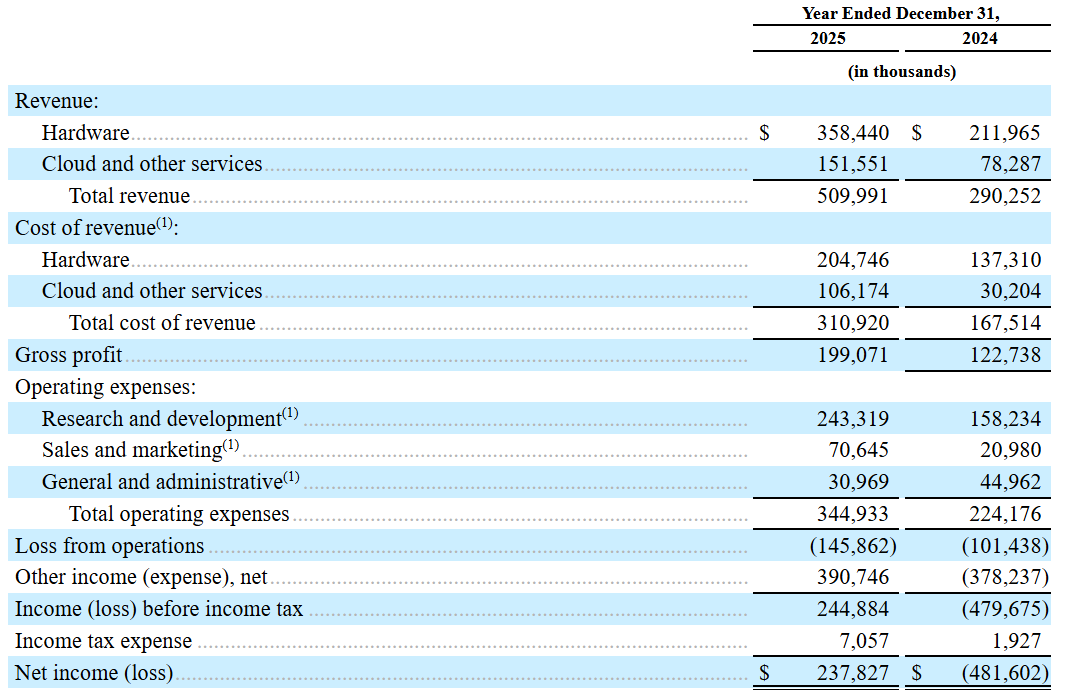
Around one-third of operating losses are non-cash, but dilutive costs, in the form of share based compensation:
As already mentioned, warrants will be deducted from revenues which will give some revenue headwinds:
“When we begin to recognize contra-revenue amounts from the warrants in the first quarter of 2026, we expect quarterly revenue growth rates will decline from recent trends.”
Gross margins are fairly low at around 40% but this is still a small scale business. If the company can successfully scale up to provide compute-as-a-service to AWS and OpenAI, long term gross margins should be fairly attractive.
The two partnerships (so far)—with OpenAI and Amazon AWS—are with two of the biggest players when it comes to AI accelerator demand. This does give validation of the tech Cerebras has built. Another proof point is Nvidia’s acquisition of Groq’s SRAM-based inference tech, swiftly integrating the solution into a single disaggregated, high performance inference platform.
Next, we’ll go through our view on valuation and what we’ll be looking for at the IPO.