
AI Outlook – Nvidia vs Broadcom vs AMD
+ a strong supplier in the humanoid robotics value chain

AI Outlook – Nvidia vs Broadcom vs AMD
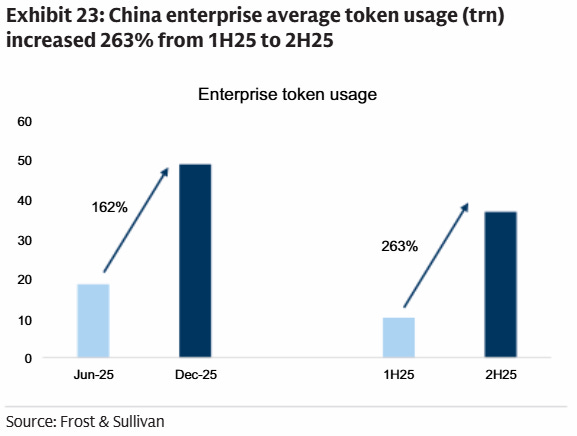
On all metrics, token consumption is exploding. According to OpenAI’s recent enterprise report, API token consumption for reasoning increased 320-fold year-over-year. In the meanwhile, the current shift to AI agents—which communicate with each other over multiple steps—is again compounding reasoning volumes. Goldman notes that China enterprise token usage grew 162% from June to December, while China is even more short on compute than the West:
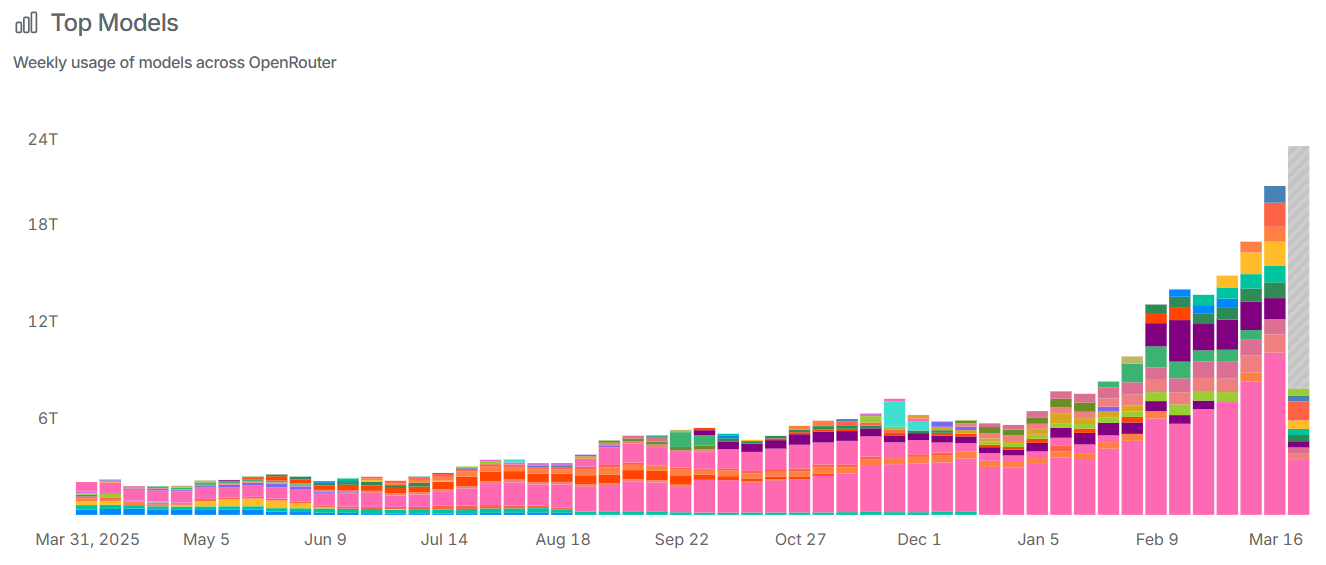
We can see on OpenRouter’s data that token consumption growth has strongly accelerated again as from January of this year:
While optimization techniques and hardware improvements have been driving sharp declines in the cost per token, demand is ramping at such a fast pace that capacity remains the binding constraint. This is UBS on OpenAI’s presentation at GTC:
“The cost of intelligence continues to fall rapidly, but demand growth still appears likely to keep the world compute constrained. The speaker highlighted sharp declines in token costs (99.7% decline in 3yrs) driven by both hardware and software improvements, while also suggesting demand is ramping fast enough that long-term compute availability remains a binding constraint. The broader implication is that “gigawatts” alone are too coarse a metric, with the shape and composition of compute becoming increasingly important as workloads diversify.”
A key focus in the coming years is on reducing latency. You don’t want a software engineer that costs $300-500k per year to sit idle for too long as he waits while Claude is generating code. This is again UBS on this trend after watching the presentation from Nvidia’s Bill Dally and DeepMind’s Jeff Dean:
“Models have improved materially on coding, math, and longer-running agentic workflows, with inference speed now emerging as the next key bottleneck. The panel suggested that agents can already sustain materially longer autonomous workflows than a year ago, with the next step less about raw capability and more about scaling throughput and lowering latency so agents can operate at practical speed (that far exceeds human speed). In that new paradigm, certain software tools developed for use at a human speed may need to be reimagined for much faster agentic workloads.”
This is the reason why Nvidia is now bringing to market a unique and low latency inference solution. Whereas Nvidia’s Rubin GPU will handle the memory-intensive prefill phase with its massive capacity of HBM, the new Groq LPX chip will accelerate the token generation in the decoding phase. Essentially, Groq LPX is a chip that heavily makes use of SRAM, resulting in an extreme amount of bandwidth and thus low token latencies:

This is Jensen on this new solution for high-performance AI workloads:
“So we acquired the team that worked on the Groq chips and licensed the technology, and we’ve been working together now to integrate the system. At the most valuable tier, we’re now going to increase performance by 35x. I would add Groq to maybe 25% of my total data center, and the rest of my data center is all Vera Rubin.
The reason why Groq was so attractive to me is because their computing system is a deterministic data flow processor. It is compiler scheduled, meaning the compiler figures out when to do the compute as the data arrives at the same time. All of that is done statically in advance and scheduled completely in the software.
The architecture is designed with massive amounts of SRAM, it is designed just for inference. And as the world continues to increase the amount of high-speed tokens it wants to generate, the value of this integration is going to get even higher. We’re going to fuse Groq and Vera Rubin, and use Groq to process the very last stage of auto regressive language models. That last stage is extremely bandwidth-intensive.
It would take a lot of Groq chips to be able to hold the parameter size of Rubin as well as all of the KV Cache that has to go along with it. So that limited Groq’s ability to really reach the mainstream and take off, until we had a great idea. What if we disaggregated inference altogether with a piece of software called Dynamo so that we could put the work that makes sense on Vera Rubin and then offload the low latency, decode generation part of the workload on Groq. And so we unified processors of extreme differences, one for high throughput and one for low latency.
It still doesn’t change the fact that we need a lot of memory. And so we’re just going to add a whole bunch of Groq chips, which expands the amount of memory. And so for a 1 trillion parameter model, we have to store all that in Groq chips. However, it sits next to Vera Rubin, where we hold the massive amounts of KV Cache that’s necessary in processing all of these agentic AI systems. So, the attention part of decode is done on Vera Rubin and the token generation part is done on the Groq chip. We run Dynamo, this incredible operating system for AI factories on top of it, and you get a 35x increase for token generation the world has never seen.
We’re in production with the Groq chip, and we’ll ship it in the second half, probably about Q3 time frame. I want to thank Samsung, who manufactures the Groq LP30 chip for us, and they’re cranking as hard as they can. The sampling of Vera Rubin is going incredibly well. And in fact, Satya texted out already that the first Vera Rubin rack is already up and running at Microsoft Azure. We have now set up a supply chain that can manufacture thousands a week of these systems, essentially multi-gigawatts of AI factories per month inside our supply chain.”
Groq LPX in combination with Rubin especially boosts the bandwidth and thus the interactivity per user:
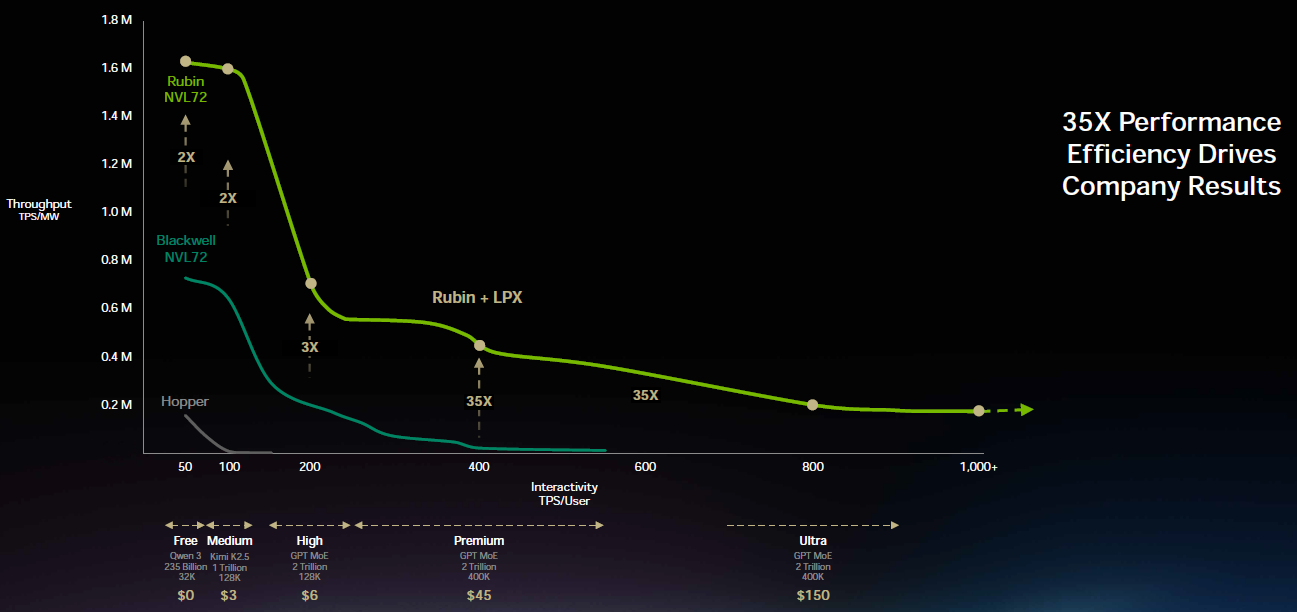
UBS came away thinking that the risk-reward is towards the upside of their revenue estimates:
“In a very well attended session, management highlighted the potential sources of upside to the updated backlog slide presented yesterday and we walked away a bit more optimistic as to how much LPX (the new fast inference solution from Groq) could add in C2027. We took from the discussion that ~$50B could be a reasonable estimate of how much LPX would add on top of the ~$460-470B implied baseline for data center revenue in C2027. On top of this, of course, would be additional business that comes in within lead times – which could be as high as ~$50-75B or even more. This is because we estimate data center will end up at least $40-50B higher in C2026 than what was implied when the company first provided this backlog last year – ergo, with 21mos still left until the end of C2027, the company should be able to add at least this much to C2027. So net of all this, we could see a data center revenue number potentially pushing $600B in C2027 (UBSe ~$520B).”
The golden question is how AI demand will come in over that fiscal ‘29-’31 period for Nvidia, as we already know that this year (FY27) and also next year (FY28) will come in strong. However, the market is assuming we’re now heading close to a peak in terms of AI capex spend which we can also see in UBS’ numbers:
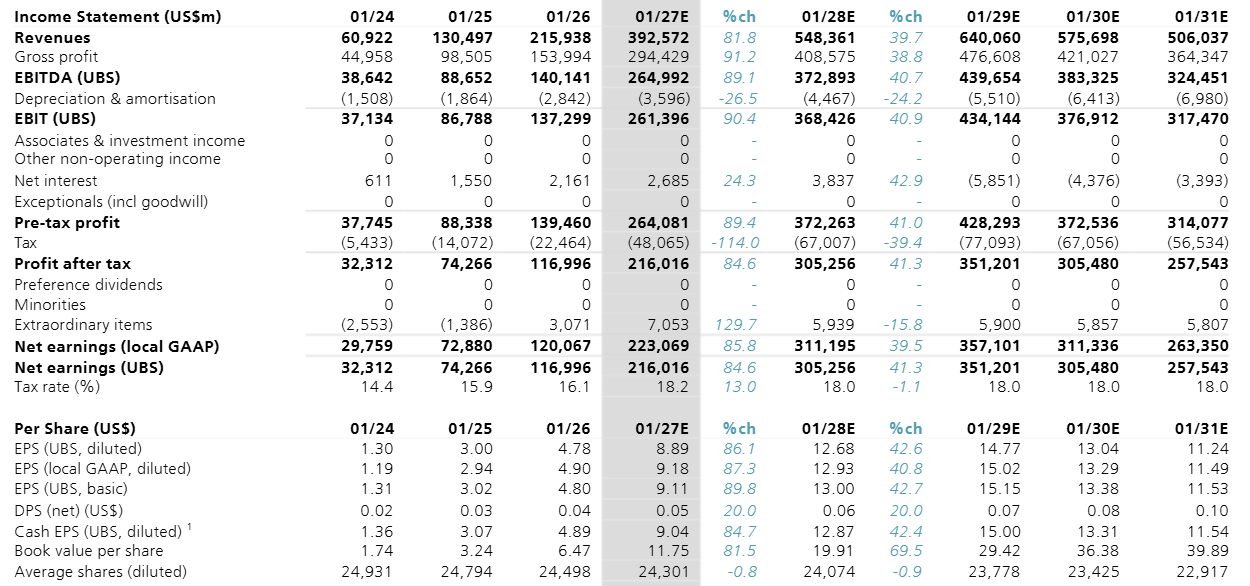
As a thought exercise, we tried to estimate Nvidia’s future annual revenues based on where AI demand will go five-six years from now in 2031. We start from current AI capacity, which is basically the sum of Nvidia’s revenues over the last three years. So, this should be roughly the current installed base excluding Google’s TPU-based data centers. This results in $407 billion of current AI capacity.
We know that this is by far not enough—the market is still undersupplied while token consumption will continue to explode. If we assume that current AI capacity satisfies 10% of future AI demand in 2031, we need an installed base of just over $4 trillion of Nvidia equipment by 2031. If we assume a lifespan of 6 years for this equipment, that demand will be fulfilled by the equipment Nvidia ships over the 2026-2031 period (6 years in total). This would mean Nvidia would sell on average $678 billion of equipment per annum in this time period:

AI demand going up 10x by 2031 is our personal best guess. Of course, it could easily be 15x, or it could only be 5x. There are a lot of moving parts—on the one hand, models are growing larger but also optimization techniques for inference are driving the cost per token down. What we feel very confident about however is that we’re very early in the adoption curve. This can easily be witnessed in the steep growth in token consumption, as well as the continuously expanding use cases of AI—from coding and AI agents in SaaS to realistic video generation, robotaxis, humanoid robotics etc. This is UBS on how AI agents will become an important driver for SaaS revenues for example:
“Also particularly intriguing to us was the CEO’s perspective that the future for software industry with AI, might shift toward monetization focused more on AI token reselling instead of historical software tool licenses/SAAS. In this new paradigm, future software companies’ COGS increase and come in a form of token consumption. At the same time, NVDA expects cloud business model to evolve from instance rentals to monetizing tokens per second (with various tiers offered at different prices). NVDA sees hyperscalers aiming to optimize tokens-per- second-per-watt.”
However, a potential problem for Nvidia is that all hyperscalers are developing their own ASIC accelerators and will gradually shift more demand towards this in-house silicon, similarly to what happened at Google already. Or what has been happening in the data center CPU market with the shift towards Graviton ARM-based CPUs at AWS. This is William Blair on Meta’s recent progress with MTIA as an example:
“In a blog post yesterday, Meta provided greater details on its custom ASIC roadmap. Meta noted that the current generation of MTIA 300 chips is already in full production, with three additional generations targeted for release in 2026 (MTIA 400) and 2027 (MTIA 450 and 500). All four generations leverage Broadcom as a key design partner, with the company contributing significant IP for I/O, networking, and chiplet connectivity. Recall that on its most recent earnings call, Broadcom noted it expects Meta to deploy several gigawatts of its next-generation XPUs in 2027 and beyond. The announced roadmap provides greater details on the design priorities for these new chips (with a refocus on LLM inference) and helps instill greater confidence that Meta will be able to scale its ASIC deployments over the next few years.”
We know that hyperscalers will be aggressively ramping ASIC capacity from Broadcom’s calls. This is from JP Morgan:
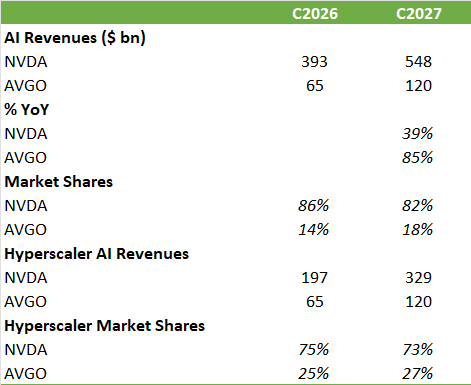
“We expect Broadcom to generate close to $65B+ in AI (ASIC + networking) revenues in FY26, led by its primary TPU customer, Anthropic ramp, the first- generation ramp of SoftBank/ARM XPU ASIC programs, and incremental revenue contributions from other AI ASIC customers such as Meta and Bytedance, along with continued strong AI networking revenue. For FY27, Broadcom anticipates close to 10 GW of total compute capacity being deployed across its six XPU customers. Specifically, OpenAI has now become a qualified customer and is expected to deploy over one gigawatt of compute capacity. Anthropic’s order deployment is projected to increase 3x Y/Y in FY27 to 3 GW. Meta remains on track with its internal ASIC program, with multiple gigawatts expected to be deployed in FY27. Customers 4 and 5 (which we believe to be SoftBank/ARM and Bytedance, based on a process of elimination given Broadcom’s disclosures) are expected to have strong shipments this year and more than double in 2027. All of this is in addition to the continued strength of Broadcom’s lead customer and the ramp of the TPU v8 (Sunfish) program. Overall, we estimate Broadcom can drive $12–15B of revenue per gigawatt and conservatively see AI revenues at $120B+ in FY27. Reflecting increasing AI customer diversification, we estimate Google TPU business will decline to less than 45% of overall AI revenues in FY27, down from 50–52% in FY26 and 60% in FY25—even as total AI revenues grow to over $120B in FY27.”
Based on these numbers we can do some modeling. We know that Nvidia makes around 50-60% of their revenues from hyperscalers, so if we then compare these revenues to Broadcom’s AI revenues, we know that Broadcom will grow its market share at the hyperscalers to around 27% by next year:
Will ASICs disrupt the Nvidia investment case? Next, we’ll dive further into developments in AI and three trades we’re making.
Additionally, humanoid robotics should be one of the big growth stories in tech in the coming decades. While the robotics field is competitive, we recently came across a well-positioned components supplier with good engineering prowess that started signaling high growth from both humanoid and quadruped robotics in the coming years. Typical investment criteria we look for are—high market shares and margins, combined with a long runway of growth so that we can simply buy and hold for the next 5-10 years with the aim of seeing shares compound into attractive multibaggers.