
Agentic AI Winners
Key findings in AI & Tech

Marvelous Marvell
The AI data center is splitting into two. On one side, you have Nvidia’s completely integrated kit—the extreme co-design that Jensen loves talking about. On the other side is the ASIC world where hyperscalers are designing custom solutions to get access to cheaper tokens, and to not be fully reliant on Jensen’s shop.
Marvell’s VP of Investor Relations is a semiconductor veteran and he tends to give much better insights on what’s going on at the company and in the industry, as opposed to CEO Matt Murphy who’s gotten a bit too salesman-like for our taste. All he does these days is talk about how pumped he is and how big the numbers are going to be in the coming years. So, the IR did a much better job detailing Marvell’s strategy in the AI data center at the Evercore conference, and we’ll go through some key insights below.
First, Marvell’s strategy is to become a bridge between the ASIC world and the Nvidia world in the AI data center:
“If you think about hyperscalers, they’ve really got 2 different infrastructures, and they don’t talk to each other. In the long run, that’s not how you want to build a data center. You want complete fungibility. That’s where Marvell comes in, with our networking IP and our custom IP. We have the bridge between both those worlds. Now, you can have hyperscalers being completely fungible in terms of how they design their network. So, we see that as really opening a much bigger TAM for the two companies combined [Nvidia and Marvell].”
A big theme in AI is scale-up—linking more XPUs together and make them behave like a single XPU—and Marvell’s goal is here to become an integrated shop which can offer all the various tech involved, whichever way the hyperscaler wants to go:
“Scale-up is almost a perfect example where a customer can work with us on the entire rack-scale infrastructure upfront. We can design all the chips for them, the entire signal path, give them different optimization paths, and this is a fairly unique ability. So, when you want to build a scale-up network, there’s 3 key components. There’s a compute engine, the XPU. There’s the interconnect, which is copper today going optical over time. And then the switch. We have all 3 pieces—we build XPUs, we’re investing in switches, and we have the leading photonics technology in the market.
On top of that, each hyperscaler is looking at multiple different alternatives, this is where our breadth of technology and investment lets us do multiple flavors. So we’re not making a bet on any one single thing. In optics, we have 3 different modulator technologies for doing scale-up optics. It’s MRM, Micro-Ring; MZM, Mach-Zehnder; as well as EAM, Electro-Absorption Modulator. We’re also investing in even more exotic technologies, whether it’s microVCSEL, or microLED. So, pretty much all options on the optical side are available. Even on copper, we can do co-packaged copper (CPC) if that’s what customers want initially as they go towards NPO and CPO.
Similarly, on the protocol side, on the switch side, we’re not restricted to offering one type of technology. We have a UALink switch coming out now, it’s 115T product. We have an ESUN (Ethernet Scale-Up Networking) product, which is based on a 100T platform. And of course, with NVIDIA, we have the NVLink platform.”
What should become a crown jewel in interconnect is recently acquired Celestial AI, which developed a photonics fabric that can connect hundreds of XPUs across racks and make them behave like a single XPU:

Celestial AI has a big win with a major hyperscaler (Amazon) and its photonics solution is on track to ramp in ‘27 and ‘28, with already $1 billion of guided revenues for calendar ‘28.
Deepening its portfolio of advanced optical tech, Marvell also acquired Polariton. This is a spinoff from ETH Zurich that has developed a unique solution to increase modulator speeds with 10x.
The bear thesis on Marvell over the past years was that their stronghold in optical PAM DSPs—where Marvell dominates with a 70% market share—would get disrupted by Broadcom. However, we’ll make two key points here. First, this is a high growth market and so even with share losses this would remain a high growth business for Marvell. Secondly, hyperscalers want multiple suppliers and so we were always skeptical on the thesis that hyperscalers would shift even more of their spend towards Broadcom, which is already the gorilla in datacenter networking.
On the other hand, we see hyperscalers keen to work with a variety of niche silicon suppliers, including Astera, Credo, etc. So, our thesis remains that hyperscalers will continue to spread their budget among this wider group of networking silicon providers, as opposed to consolidating their spend with Broadcom. Marvell’s IR mentioned how their interconnect business remains on fire:
“Our interconnect business is growing at 70% plus for this year. Within that, there’s really 2 big underlying drivers. There’s a scale-out business that’s growing even faster, that’s our PAM DSP and TIA driver business. And then you’ve got scale across, which is just starting and is going to get a lot bigger in the outer years. So, the short to medium term from a revenue perspective looks very strong. And then what’s even more exciting is all the engagements we are seeing a little bit further out in time.
On competition in DSP, the basis of competition in these markets is always “were you first to market?” That’s been the case in every single generation of PAM4, and it’s no different at 1.6T. The largest part of our interconnect business is our PAM DSPs, and next year, 1.6T is a huge part of it. The reality is I don’t think we see anything significantly different. We’ve had a leading position, and I don’t really see that changing going forward.”
Marvell is supplying the DSP, the driver, and the TIA:
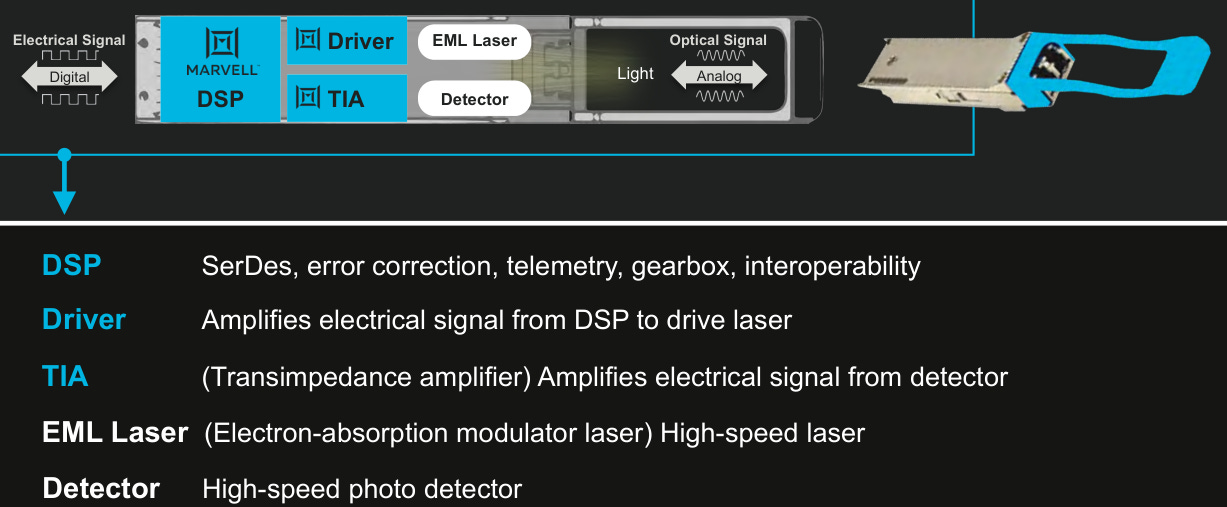
And with silicon photonics the company can even sell an extra die (a SiPho PIC, or Photonic Integrated Circuit):

The other bear thesis on Marvell was that they didn’t know what they were doing in custom ASICs and would lose those programs to Broadcom. However, also this bear thesis took a massive dent over the last months as Anthropic is currently training the most advanced LLMs on Trainium clusters. At the same time, Amazon is massively scaling up its AI capacity and is doing this on a mix of Trainium and Nvidia infrastructure. The key platform in AWS’ AI strategy is Bedrock and that is largely running on Trainium. Hyperscalers are extremely good at writing intermediary software layers to run workloads over a variety of underlying hardware, something which will only become easier with Claude Code.
Thus, all data points are pointing to Trainium being a massive success, and Marvell will remain a key partner in this program going forward. JP Morgan notes that Marvell is working on the design for the 2nm Trainium 4 chip, as well as a large number of other ASIC programs including the Microsoft Maia XPU:
“In custom AI ASICs, the next-generation Trainium 3 XPU ASIC program is starting its initial shipment ramp this quarter, with volumes increasing in the second half of the year. We believe the team [Marvell] is deep in the design phase of the next-generation Trainium 4, 2nm program. Their next Tier-1 XPU customer (Microsoft, Maia 3nm XPU program) is progressing well, with plans for high-volume manufacturing next year. Relative to the Microsoft demand forecast, we believe Marvell is still being very conservative (FY28) and taking a significant haircut to the actual forecasted numbers. The team has 10+ XPU attach programs ramping next year (DPU, CXL, networking). Overall, we are impressed with the strong multi-year revenue outlook and the diversity of customer program ramps, and we see a solid setup for CY26/ CY27.”
Evercore’s background checks point to Marvell being a key partner for these programs:
“Over the last 6 months, we talked to about a couple of dozen sources amongst the hyperscalers. And very consistently across the group, what we heard is that Marvell is being viewed more as a more strategic partner supplier. And that’s because the broad portfolio of IP, not just on the XPU side, but also on the networking side.”
Marvell’s IR explains their role in XPU design, versus where competitors in Taiwan such as Alchip play:
“The reason why customers are coming to us is because there’s a lot of our interconnect technology when you build large complex XPUs. These XPUs are no longer monolithic single-chip devices. These are multiple compute dies and HBM stacks. So you need high-speed SerDes, you need die-to-die interfaces, you need custom HBM interfaces, you need much more optimized custom SRAM for much higher packing density, you need advanced packaging, and those are all things we do for our merchant business. So the reason we’re in the custom business is because of the expertise we’ve established from our merchant business.
Now when you build a chip, there’s an IP portion, which is more considered kind of front-end design, but right at the end of the process, you have to do layout, which is physical design. So some of the design service companies have an important role in the ecosystem, but they don’t have IP. And the reason they don’t have IP is because they don’t have a product business. That’s the real distinction. If we are engaged in a project, it’s because our networking IP is what the customer is looking to access and build into the XPU, versus when they’re partnering up with somebody in the design services side, it’s more of a relationship where you need someone to do the last part of the process, which is physical design.”
One example of specialized IP is Marvell’s SRAM with higher packing density, which enables 17x the bandwidth versus off-the-shelf IP according to the company. Marvell illustrates how this will be useful for both 2nm accelerators and CPUs:
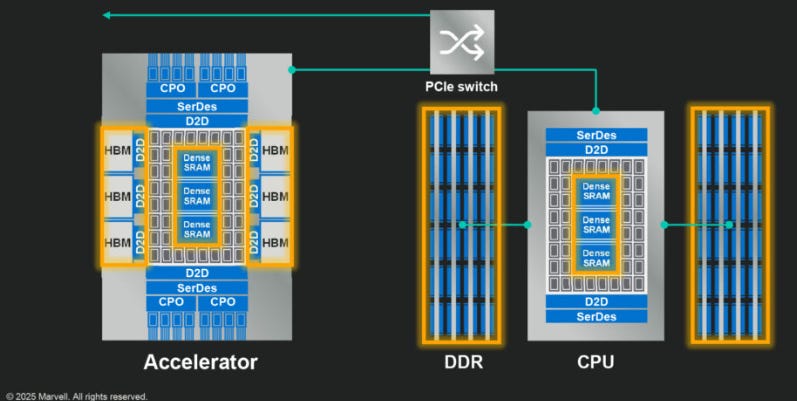
And then also XPU attach is a big opportunity for Marvell. XPU attach is basically companion chips that can take background tasks over from the XPU, allowing the XPU to focus on key AI workloads. This is Marvell’s IR on this market:
“Think about XPU attach as an offload device. You’re trying to maximize your central compute device for its core function. This is no different than years back, where you started creating NICs to minimize I/O of the server CPU. Same idea essentially. CXL and NICs are the two large examples, but there’s a couple more design wins going into production. One would be storage accelerators. Whether it’s SSDs or HDDs, instead of having the core CPU or XPU address them, you’d rather do it on a dedicated device. So that’s a storage accelerator.
And another one is the security offload device. This is a unique product for Marvell, and comes from the Cavium acquisition. We’re one of the only companies building dedicated security accelerators. The idea is that I want to make sure my data when I put it into a cloud network is encrypted. You can certainly do encryption/decryption on a standard XPU or a standard CPU, but why would you? You’d much rather do it on a dedicated device. So that’s another example, which is again going to be a fairly large opportunity for us.”
Millions of XPUs are sold annually, and so if you can cross-sell $1,000-$2,000 worth of silicon that goes alongside these XPUs, this is obviously a big opportunity. Marvell is guiding for $3 billion of revenues in FY28 to come from XPU attach. Both CXL and custom NICs are $1 billion opportunities each.
And this opportunity continues to increase with agentic AI—if you need more CPUs, you need more NICs. And as agentic AI creates more KV cache data, this means also CXL will be needed. CXL is basically an interconnect that lets XPUs treat external DRAM as if it were directly attached to the processor. This way, excess KV cache can be moved from HBM to CXL-attached DRAM.
Overall, we like Marvell’s strategy. The company is clearly building out a portfolio of some of the most cutting edge tech in both AI data center networking and custom silicon. Recent acquisitions like Celestial AI and Polariton are good examples of this strategy and seem once again like very smart strategic moves by Matt Murphy. So, we liked the risk-reward in this name a lot over the last twelve months, as the shares were trading in the low twenties on a forward PE basis:
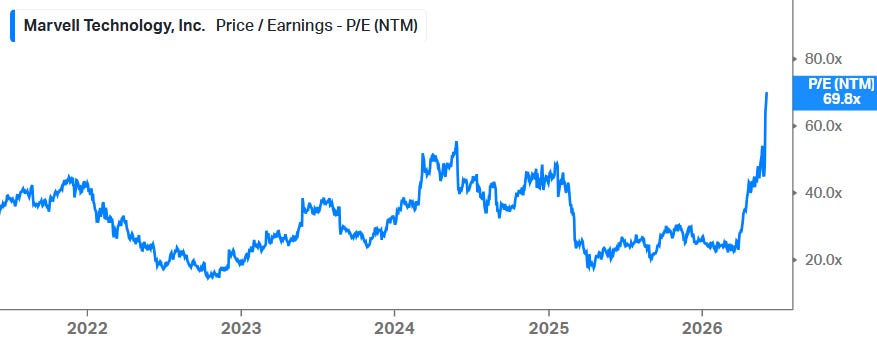
However, after Jensen decided to pump the stock in Taiwan, we’ve now moved to a 70x forward PE valuation. For the bulls, we actually don’t think the shares are massively overvalued now—it’s likely that numbers are still too low given the emergence of agentic AI, and so we can move towards $10 of EPS already in calendar 2028. This gives a current valuation of around 30x 2028 numbers.
However, this valuation now warrants absolutely flawless execution. At the same time, we suspect that a lot of the speculative and fast retail money has now moved into the stock—the kind of crowd that buys based on a meme or a news headline. In our view, these two factors make the risk-reward now unattractive, with likely a substantial correction again at some stage. After shares rose 30-35% post Jensen’s comments, we decided to liquidate our position. We do love Jensen, somehow this guy always figures out a way to make us some nice profits.
Server CPUs Are A Hot Market Again
At Computex, Nvidia illustrated how the CPU has become important again in agentic AI workloads:
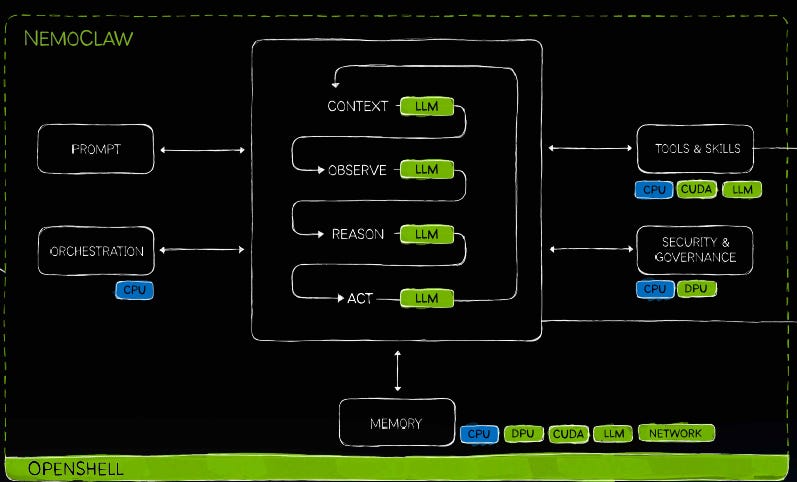
However, it’s also clear that the accelerator (GPU/XPU) will remain dominant as this is where all the reasoning happens. On the other hand, when the AI has to make a database call, do a web search, or execute a Python script, this happens on the CPU. So, the GPU writes the Python script, and then the CPU executes it.
Jensen highlighted at Computex how CPU performance becomes crucial in agentic workloads, from a transcript created by Claude:
“Huang argued that all CPUs until now were created for people — humans who live in a world counted by seconds, who rent CPU cores in the cloud at hourly rates. Agents are fundamentally different. They are impatient. They live in a world counted in nanoseconds. When an agent uses a tool or accesses a database, the response must come back as fast as possible. Every moment of waiting keeps the agent from proceeding to the next step. And because CPUs sit in the critical path next to extremely expensive GPU infrastructure that generates token revenue, these CPUs must be both high-performance and highly energy-efficient.
A narrated video elaborated on the Vera CPU’s technical architecture. The NVIDIA Olympus core at the heart of Vera is built for modern data center workloads including branch-heavy Python runtimes, tool calls, and sandbox code execution. The video described Vera achieving 40 percent lower peak memory latency versus x86. Memory-coherent NVLink chip-to-chip connects GPUs directly to the CPU and can also scale Vera up to multiple sockets. Vera delivers 1.8 times the agentic sandbox performance of x86 CPUs.
Returning to the stage, Huang presented benchmark results. He showed SQL running three times faster on Vera—calling it extraordinary since SQL is among the most difficult workloads to accelerate. He also presented real-time stream processing results for the New York Stock Exchange, where Vera CPU runs six times faster, crediting the bandwidth improvements, single-threaded instruction execution, and internal and external bandwidth improvements of the architecture.”
UBS notes that Nvidia will be doing more CPU revenues than AMD this year, which also includes standalone CPU sales for Nvidia:
“Maybe the most controversial item was new disclosure that “standalone” Vera CPU will be ~$20B in revenue this year and opens up a new $200B TAM. On the surface, this is a much larger number this year than we would have expected and is even bigger than AMD which we model to be ~$16B this year and has >50% share in the cloud segment. In speaking with the company, there are some clear use cases that are standalone chips (e.g. CPUs attached to non-NVDA accelerators, for example, META as part of its recently signed Vera CPU deal) but this also includes “standalone” systems that only have a CPU with no GPU. It is hard to say, but in these configurations, the standalone CPU chip might be ~30% of the total value with DRAM being another large component. So NVDA may only be doing ~$5-7B of CPU chip revenue this year - which would imply ~1-1.5MM units - which makes sense to us. Regardless, NVDA’s forward thinking on supply should especially come to bear in this agentic world where newcomers like ARM and even QCOM are competing for capacity and we read this as negative for the aspirations of these other competitors.”
Similarly, Qualcomm—the leader in power efficient smartphone CPUs—is now looking to deploy their skills and take share in the data center CPU market:
“The second area where we’ll be entering the data center is the CPU. As you might know, we have a custom CPU that we deploy in handsets, where we are the performance leader. We also deployed that same CPU in PC. And so if you compare us to the x86 players, Intel or AMD, we think we have a very significant performance advantage. And we’re going to bring all of that to bear in a data center CPU solution. CPU use is changing in the data center, and it’s a very large market.”
Even ARM is looking to compete with their own customers and has now launched its ‘AGI CPU’:
“As AI is moving from human-based queries to continuous agent-driven workloads, this shift is expanding the role of the CPU. These Agentic workloads require CPUs to coordinate tasks, move data, manage memory, enforce security and orchestrate workaround accelerators. As Agentic AI scales, data centers will require more than 4x today’s CPU capacity, creating a data center CPU market opportunity of more than $100 billion by 2030. The Arm AGI CPU, which we launched at our Arm Everywhere event last quarter, is purpose-built for Agentic AI.
Our first production silicon product for the data center will deliver more than 2x the performance per rack compared with x86 platforms with the potential to reduce AI data center capital expenditure by up to $10 billion per gigawatt. Meta is our lead partner and co-developer, and is working with us on a multi-generation road map to support personal super intelligence for more than 3 billion users.
Customer response to the Arm AGI CPU has been very strong. We now have more than $2 billion of customer demand across fiscal 2027 and fiscal 2028. This is more than double what we stated at launch. We are on track towards our forecast of $15 billion as stated at our Arm Everywhere event. And soon, the data center will be Arm’s largest business.
For example, SAP will move their core database and business application workloads to Arm, starting with AWS Graviton and expanding to the Arm AGI CPU. This represents a significant strategic shift. Cloudflare will deploy Arm across its global network to support traffic management, security and AI inference closer to users. We have also secured design wins with key network infrastructure providers, including F5 and SK Telecom.
AI infrastructure needs CPUs and accelerators working together efficiently at scale. NVIDIA, Amazon and Google are already using Arm-based CPUs as head nodes along the accelerator-based systems. Cerebras, OpenAI, Rebellions and Positron are doing the same with the Arm AGI CPU. This momentum builds on our existing scale in the cloud. That scale is increasingly driven by Arm Neoverse CSS and Arm-based compute, which now represents about 50% market share with top hyperscalers.”
Historically, Intel and AMD had the x86 moat which meant that all server and PC software was written to run on x86 cores. However, due to smart container-based software such as Kubernetes, the large clouds can now deploy apps inside containers which abstract away the hardware underneath. This means that apps can run on both x86 and ARM-based CPUs, which is allowing hyperscalers to move workloads to their custom ARM-based silicon.
We’re only at the start of this trend as only Amazon has scaled its Graviton CPUs so far, but also Microsoft and Google are looking to replicate this strategy. Where x86 still has a stronghold is in the enterprise server market (i.e. on-premise data centers), however, cloud is the high growth market and over the long term, we suspect that most of the public cloud will move towards ARM cores.
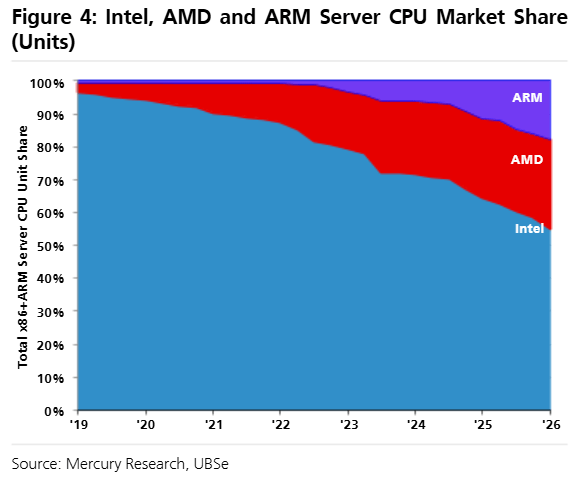
Thus, cloud CPUs will become an extremely competitive market. Nvidia has already become massive in data center CPUs, in the blink of an eye. Another giant with Qualcomm is entering as well, which has strong skillsets in power efficient CPU design. Even Arm has cobbled together a number of interesting deals such as with Meta and Cloudflare. At the same time, hyperscalers such as Amazon, Microsoft, and Google will increasingly move cloud workloads to custom silicon.
Despite increasing competition, we still see two key positives for AMD. While all hyperscalers are mainly looking to deploy a Nvidia + ASIC strategy in accelerators, AMD as a third player in the market can still make substantial money. Its GPUs with higher HBM capacity versus Nvidia are an advantage in inference, so we continue to think that AMD will be able to grab a smaller share in the GPU market, which will still be lucrative. Deals with OpenAI and Meta illustrate how the company has indeed secured share.
At the same time, momentum in the server CPU market will be tremendously strong in the coming years, while newcomers such as Qualcomm and Arm will only gradually gain share. Microsoft and Google are also still only at the start of their CPU ASIC journey. Thus, we see both AMD’s CPU and GPU businesses as booming in the coming years.
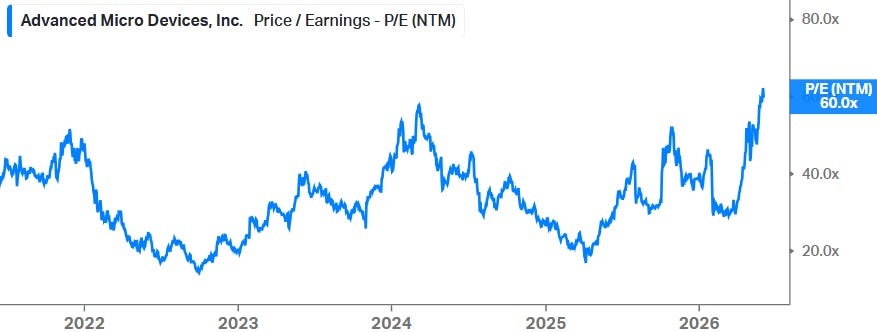
However, at 60x forward EPS, and 29x 2028 EPS, this strong story is now well reflected in valuation. So, we don’t see the risk-reward as being attractive at this stage. We could be interested again later in the year if there is a strong correction in AMD.
A negative for AMD is that capacity is extremely tight—TSMC isn’t able to meet all demand and this will also limit AMD to secure additional capacity for the boom in CPUs. This is AMD’s IR at the BoA conference:
“Supply is tight. 3-nanometer is tight. There’s a lot of other areas that are tight. I think we’re very well positioned with the relationships Lisa has personally with the executives in that space to get maybe more than our fair share of the incremental. But it is tight.”
It’s just something to keep in mind as it will limit AMD’s potential to surprise on the upside in the coming years.
Next, we’ll go through a variety of names that we see as winners from agentic AI—we’re currently halfway through the analysis.